AlexNet
据说这是大模型的起源与标志
介绍
在图像识别领域,先前的工作使用的数据集都很小,尽管在某些任务中已经达到了人类水平,但是实际情况是非常复杂的,我们需要更大的训练集
为了能从海量的数据中学到东西,模型需要有一个巨大的学习能力。但是由于数据过于庞大,这个任务不能被人力明确定义。对于分类任务,只依靠训练数据是远远不够的,我们还需要有先验知识(prior knowledge)作为补偿。而CNNs(Convolutional neural networks)正好具有这种能力
使用高清图片训练CNNs是非常昂贵的,但更幸运的是,在算力上现在GPU可以加速CNNs的训练,在数据上最近有了大量标签过的训练数据
结构
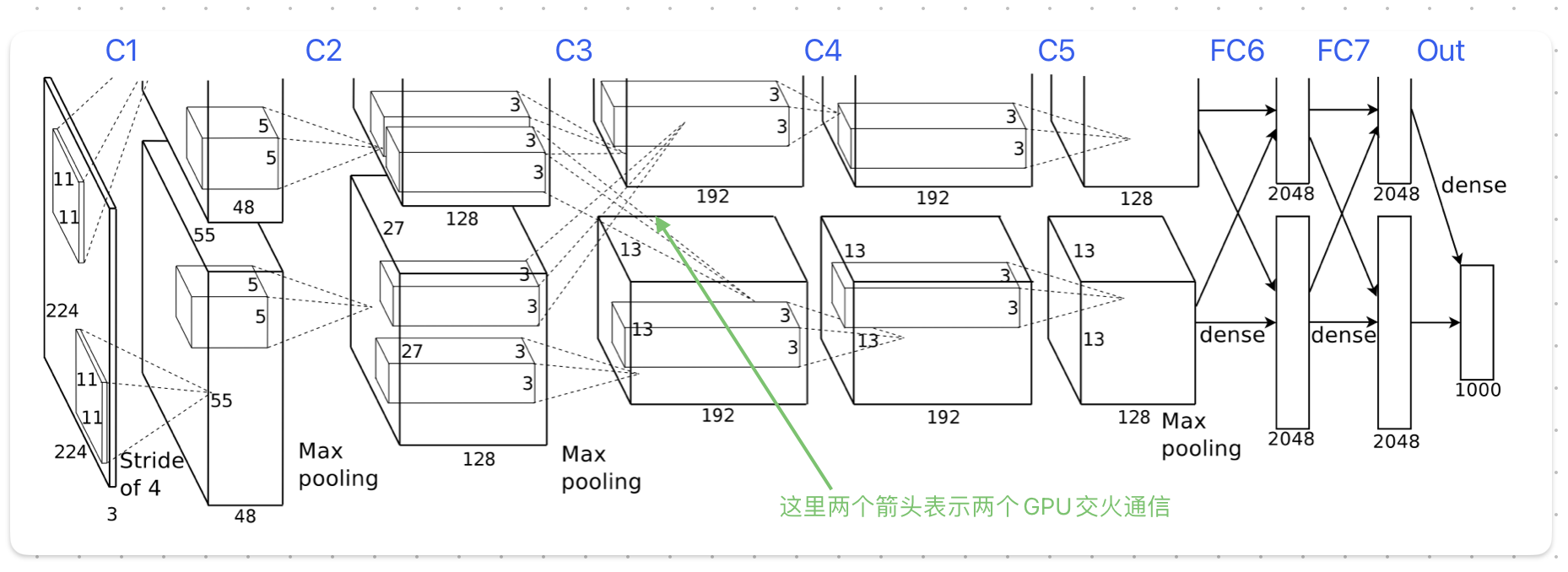
一共八层
非线性ReLU
Rectified Linear Units
作者发现使用ReLU会大幅提高训练速度
多GPU训练
单个GPU的显存太小,无法放下训练数据,由于当时显卡具有交火功能,可以直接从另一张卡中读写数据,于是作者将模型平分放在两张卡上
为了减少GPU间通信,模型被设计为好几层,只有在某些层(C3)两张卡才会进行数据通信,其他层的输入只使用当前GPU中上一层的输出,大幅减少了通信次数
LRN
Local Response Normalization
对模型的输出进行归一化,以提高模型泛化的能力
重叠池化
Overlapping Pooling
重叠池化的池化窗口在特征图上滑动时存在重叠部分。通过增加特征冗余性、减少空间信息损失、增强特征不变性、提高尺度不变性和降低特征维度等方式,有助于防止模型在训练过程中发生过拟合现象
第一层
输入224x224 (227x227)RGB图片,输出55x55x96的特征图
第一层是使用一个11x11x3的卷积核,(卷积核中心)每次移动4像素
55 = floor((224-11)/4) + 1 |
第二层
输入55x55x96,先池化为27 × 27 × 96,再卷积为27x27x256
第二层使用一个3x3的池化窗口,每次移动2像素
27 = floor((55-3)/2) + 1 |
再使用256种个5x5x48的卷积核卷积,每次移动1像素
第三层
由于两个GPU间有通信,于是输入翻倍了
第四五卷积层
第六七全连接层
全连接层和卷积层的区别
第八输出层
总结
- 第一个使用CNNs做高清图像分类任务
- 使用多卡GPU加速
- 使用ReLU激活函数