Tile Base Deferred Rendering
基于Apple M1和Metal图形库
移动端GPU渲染架构
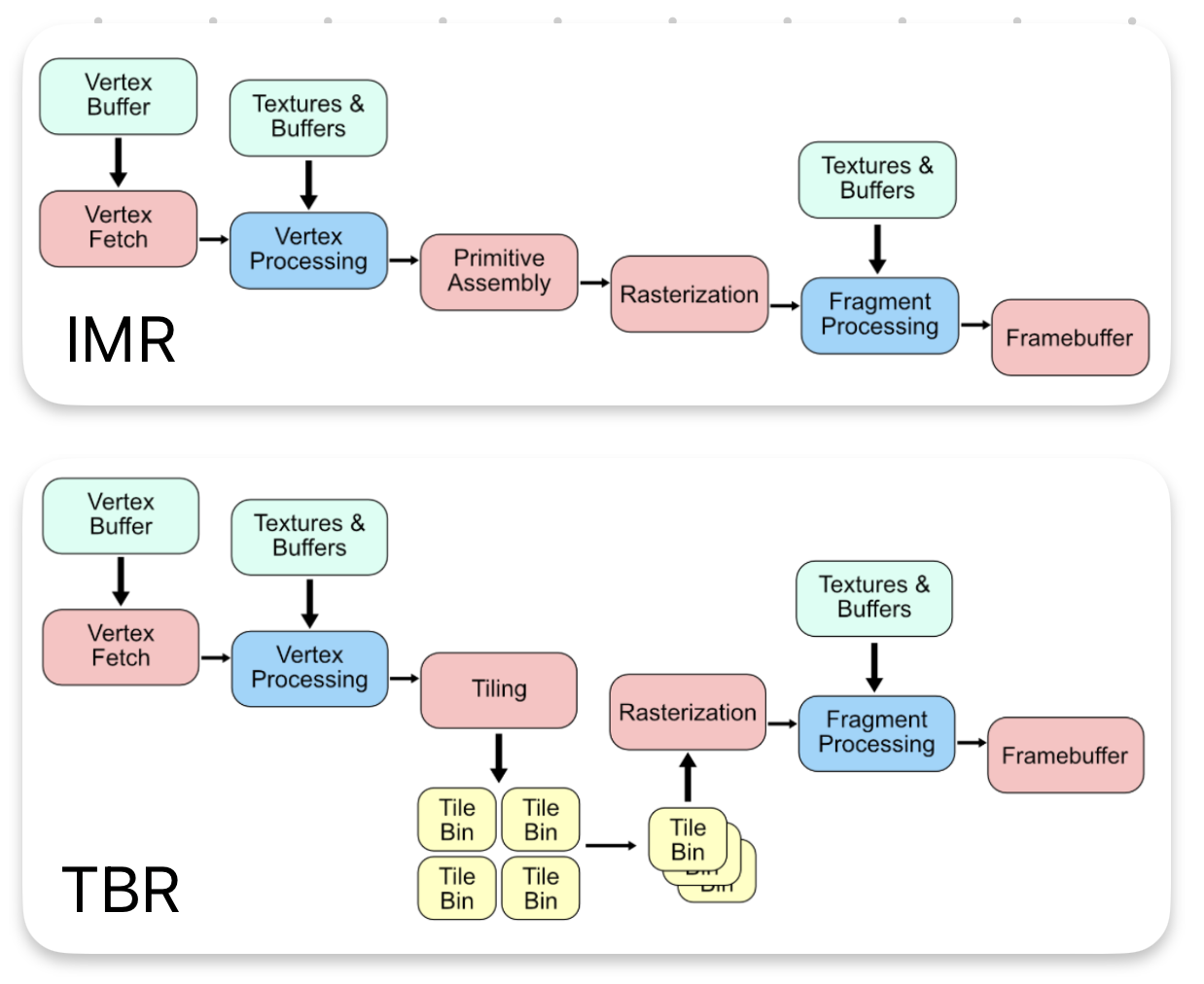
- IMR(Immediate Mode Rending),即时模式渲染,按drawcall顺序绘制
- TBR(Tile Base Rendering)
- 将画面分割为一个个tile,在VS对每一个tile处理,将结果存到On-Chip Memory上
- FS读信息,渲染每一个tile
- 当FS将所有的tile渲染完毕后,将完成的frame信息写入System Memory中
TBR相较于IMR能省带宽,而移动端的性能瓶颈在于带宽
值的注意的是,TBR产生带宽优势的核心是片上存储,而非Tile
我个人感觉为什么要使用Tile,可能是因为移动端GPU规模太小,难以放下整张RT。毕竟理论上使用一张大RT的采样成本更低,比如将一组TextureArray转化为VSM,能很明显提高滤波速度
我在实际测试中发现当你隐式使用TBR时也会自动切分Tile,手动指定Tile尺寸反而增大了带宽和GPU时间(我也不清楚为什么,希望有人能给我解释一些)
On-Chip Memory
片上存储(on-chip memory),是集成在GPU上的存储空间
GPU中有多种存储数据的结构,访问速度从快到慢排依次是
- Register Memory(RMEM)
- 访问极快,不需要消耗时钟周期(除非发生了冲突或者先写后读)
- 只对负责对其进行读写的线程可见
- Shared Memory(SMEM)
- 对处于同一个block所有的线程都是可见的,所以常用与数据交换
- Constant Memory(CMEM)
- Texture Memory(TMEM)
- Local Memory(LMEM)和Global Memory(GMEM)
- LMEM只是对GMEM的一个抽象,两者存取速度上一样的
- 只对负责对其进行读写的线程可见
- 一般用来存储automatic变量
- automatic变量是一种大尺寸的数据结构/数组
- 有缓存机制(类比cache)
其中RMEM与SMEM是集成在GPU芯片上的,其他的则是存储在显存中的(你可以类比寄存器,cache和内存)
Metal使用On-Chip Mem最大的变化就是,你不再需要在RenderPass中读取上一个Pass的贴图,传递给下一个Pass,Shader的输入值可以直接替换为上一个Pass的输出结果,并直接使用
上一个Pass的结果你也可以通过imageblock<GBufferOut> img_blk_gBuffer访问
-fragment float4 fragment_deferredSun(VertexOut in [[stage_in]],
+fragment float4 fragment_tiled_deferredSun(VertexOut in [[stage_in]],
constant Params ¶ms [[buffer(ParamsBuffer)]],
constant Light *lights [[buffer(LightBuffer)]],
- texture2d<float> albedoTexture [[texture(BaseColor)]],
- texture2d<float> normalTexture [[texture(NormalTexture)]],
- texture2d<float> positionTexture [[texture(NormalTexture + 1)]])
+ GBufferOut gBuffer)
{
uint2 coord = uint2(in.position.xy);
- float4 albedo = albedoTexture.read(coord);
+ float4 albedo = gBuffer.albedo;
- float3 normal = normalTexture.read(coord).xyz;
+ float3 normal = gBuffer.normal.xyz;
- float3 position = positionTexture.read(coord).xyz;
+ float3 position = gBuffer.position.xyz;
Material material {
.baseColor = albedo.xyz,
.specularColor = float3(0),
.shininess = 500
};
float3 color = phongLighting(normal,
position,
params,
lights,
material);
color *= albedo.a;
return float4(color, 1);
}
|
Single RednerPass
类比Vulkan的SubPass
传统的延迟渲染,是一个多Pass渲染。GBufferPass生成MRT,传递给LightingPass着色输出,这个过程中会有大量的贴图IO带宽
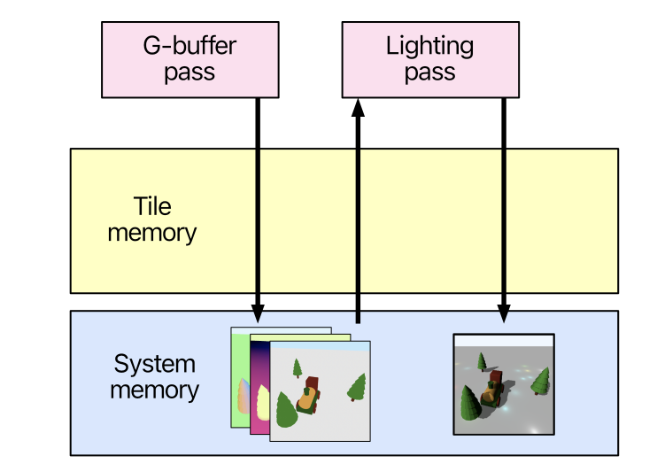
TBDR(Tile Base Deferred Rendering)利用了Metal图形库Single RenderPass的特性
- 在一个Single Pass中有多个小Pass,小Pass共享一组片上存储
- 一个Pass运行后,会在片上生成一些临时贴图,其他Pass可以直接访问这些贴图
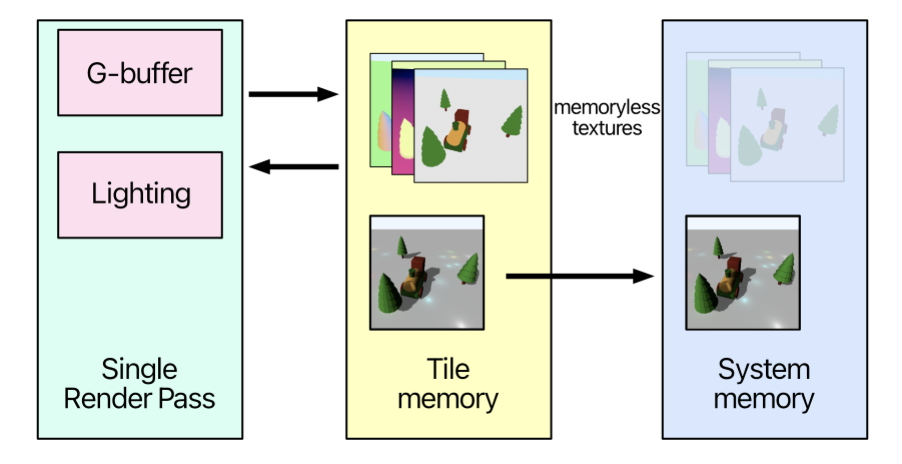
TBDR是Apple芯片的功能,对于安卓GPU
Adreno:frameBuffer fetch deferred,提前绑定(开辟)好MRT,使用时RT不动,Pass动
Mali:pixel loacl storage deferred,将GBuffer存在on-clip mem上,于是就减少了IO消耗
drawable
当我们使用MTKView呈现渲染结果时,需要指定currentDrawable
unc draw(cullingResult: CullingResult, in view: MTKView) {
guard let commandBuffer = RHI.commandQueue.makeCommandBuffer(),
let descriptor = view.currentRenderPassDescriptor else {
return
}
updateUniforms(cullingResult: cullingResult)
updateParams(cullingResult: cullingResult, options: options)
shadowRenderPass.draw(commandBuffer: commandBuffer,
cullingResult: cullingResult,
uniforms: uniforms,
params: params,
options: options)
tiledDeferredRenderPass.skyboxCube = cullingResult.skybox
tiledDeferredRenderPass.shadowTexture = shadowRenderPass.shadowTexture
tiledDeferredRenderPass.descriptor = descriptor
tiledDeferredRenderPass.draw(commandBuffer: commandBuffer,
cullingResult: cullingResult,
uniforms: uniforms,
params: params,
options: options)
postProcessRenderPass.drawableTexture = view.currentDrawable?.texture
postProcessRenderPass.preTexture = tiledDeferredRenderPass.finalTexture
postProcessRenderPass.draw(commandBuffer: commandBuffer,
cullingResult: cullingResult,
uniforms: uniforms,
params: params,
options: options)
guard let drawable = view.currentDrawable else {
return
}
commandBuffer.present(drawable)
commandBuffer.commit()
}
|
我们在TBDR时,将GBuffer和Depth设为.messoryless,并不保存,这些RT将放置在Color1~4中
albedoTexture = Self.makeTexture(
size: size,
pixelFormat: .bgra8Unorm,
label: "Albedo Texture",
storageMode: .memoryless)
...
for (index, texture) in textures.enumerated() {
let attachment =
descriptor.colorAttachments[RenderTarget0.index + index]
attachment?.texture = texture
attachment?.loadAction = .clear
attachment?.storeAction = .dontCare
attachment?.clearColor =
MTLClearColor(red: 0.73, green: 0.92, blue: 1, alpha: 1)
}
|
GBuffer Pass不输出Color0,Light Pass输出Color0,保存后传递给Post-Process Pass
其实你也可以直接将Light Pass的Color0设置为view.currentDrawable?.texture,这样Light Pass的结果会直接呈现在View上
之前在这一步卡了很久,如果你不显式保存Color0,那么最后一个Pass的Color0就会成为drawable
但如果你将Color0保存,你会发现屏幕变品红色,没有报错,截帧会崩溃,其实就是你保存Color0后没有显式指定view.currentDrawable?.texture = Color0,View没有东西可以显示
参考
WWDC 2020
Metal by Tutorials