Clustered Shading
《Clustered Deferred and Forward Shading》阅读笔记
Cluster:组,簇,一堆物体的群集,将一个个零散的小物体整合为一个Cluster,可以加速剔除
Cluster的思路跟TBS思路很像,也是将view进行切分,但是每一个Cluster拥有一个固定的三维边界(坐标和法线),于是解决了Tiles退化的问题
光照计算时需要遍历物体和灯光,Clustered Shading的目的是剔除灯光
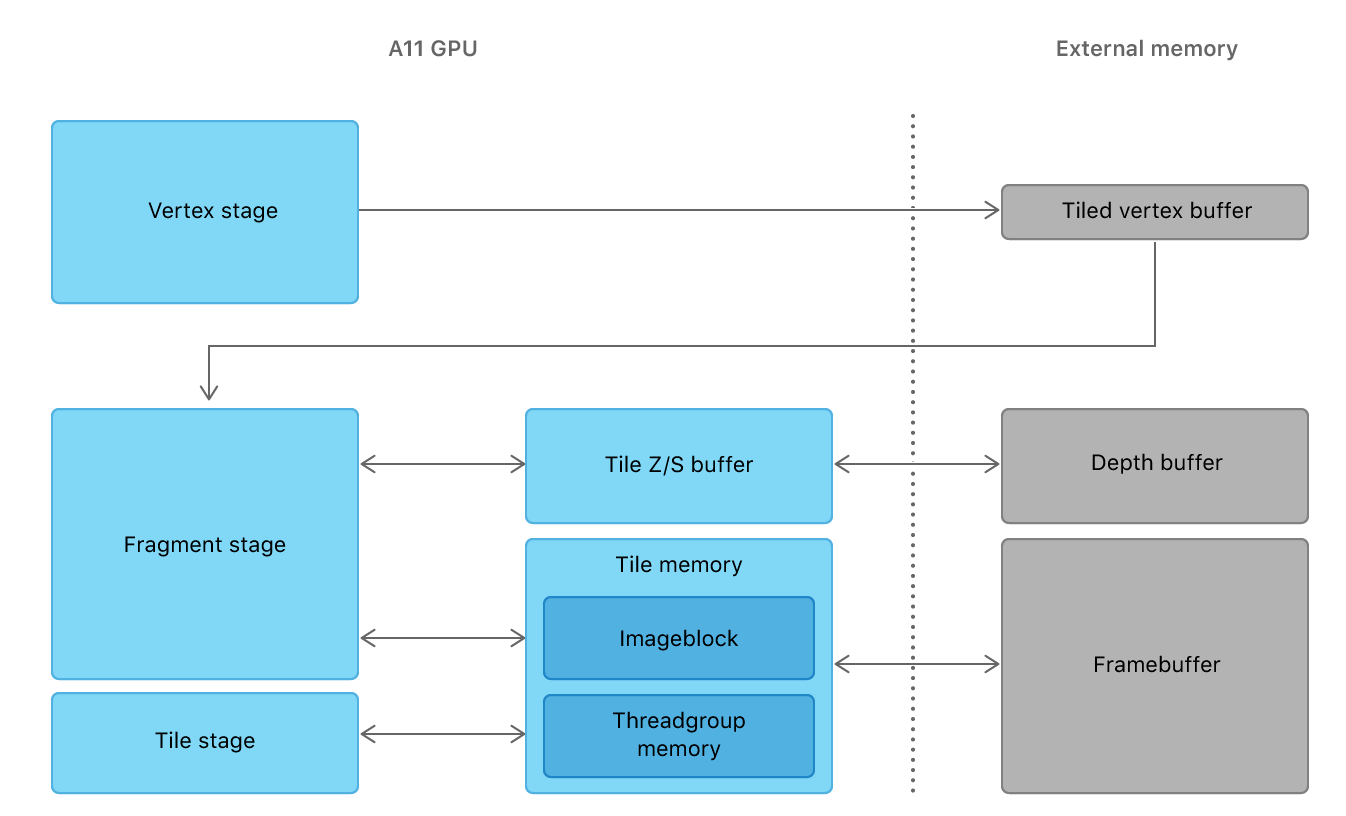
Tile base Shading
在讲Cluster前,先介绍什么是Tile base shading。TBS使用屏幕坐标将view切分为一个个小Tiles,单独绘制每一个Tiles,渲染结束后将所有Tiles合并呈现到屏幕上(得到framebuffer)
每一个Tiles会维护最小和最大深度,这两个深度和Tiles的屏幕UV就会组成一个粒度比较大的BV(Bound Volume),用于粗粒度的视锥剔除。在绘制每一个Tiles时,我只关注这个Tiles内的物体、灯光,不关心场景整体的复杂度,可以少遍历很多物体
此外这个Tiles之间是互相独立的,于是你可以自由控制他们的绘制顺序,比如如果某个像素上有两个半透明物体重叠,那么可以并行计算两个半透明物体的绘制结果,在最后一步混合时再手动排序
优点
由于每次只需要绘制一个小Tiles,于是大幅减小的最大带宽(变得细水长流)
Tiles足够小,我们可以将Tiles放到片上缓存中,只需要调整着色器而无需移动资源位置(无需在显存和内存间传递,尤其是移动端这种共用全局内存的GPU),更进一步减少了带宽
问题
Tiles的BV是不确定的,通过屏幕UV采样深度得到的第三维边界是粗粒度的,不确定的。在某些极端相机视角下,min和max可能会差距很大,而内部的深度其实不连续(也就是最前面有个物体,最后面有个物体,结果得到了一个巨大的BV)
在这种情况下,BV就退化为一个平面,大幅降低了剔除效率
相关技术
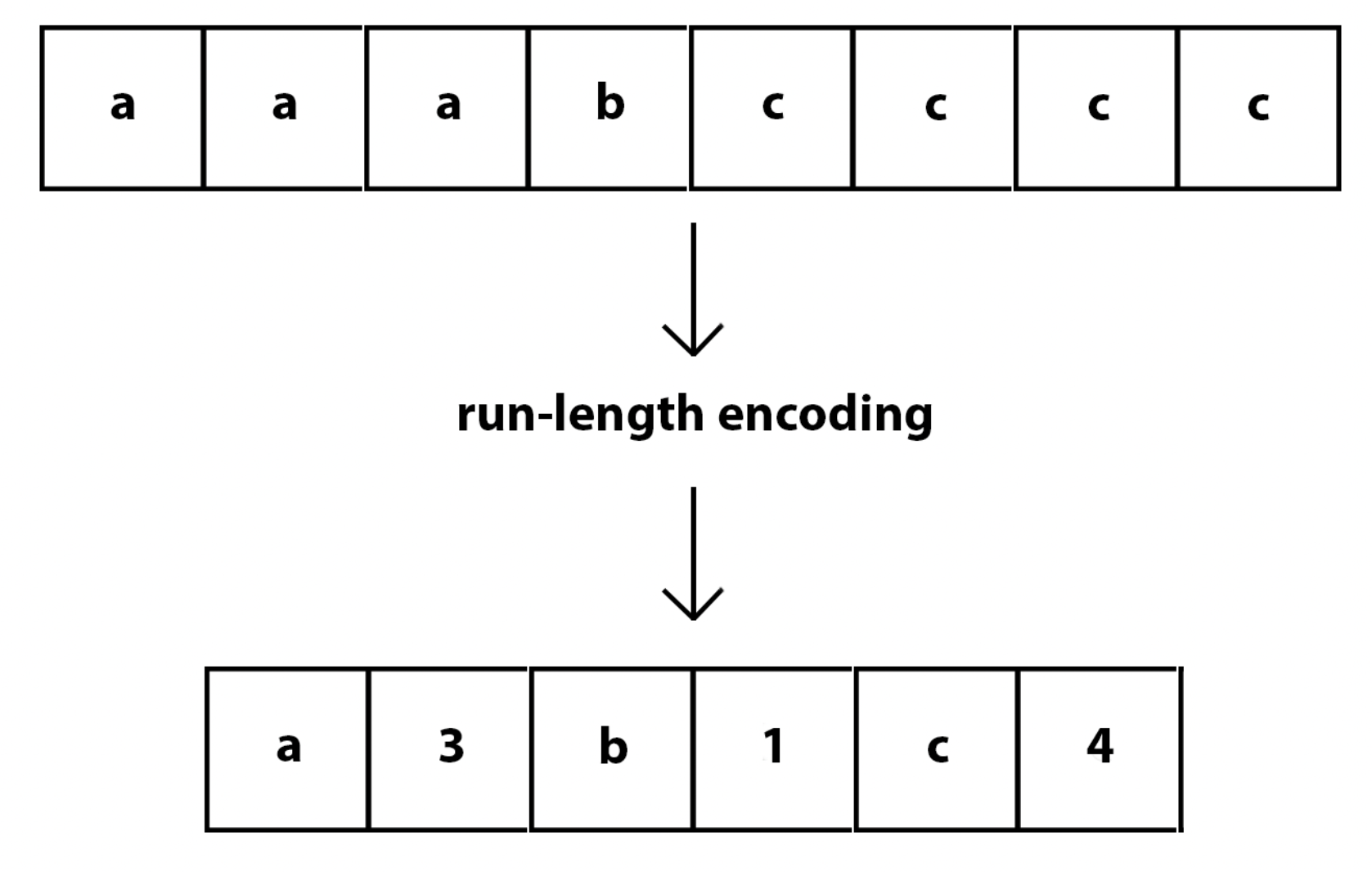
Run length encoding
RLE(Run length encoding)是一种压缩算法,该算法依赖了数据的连续性,将一个一维的有重复值的数据进行压缩,能大幅减少数据量
此外当我们要对一个一维数组排序时,也可以将数组先做RLE,对压缩后的数据进行排序,排序结束后再展开
很多渲染技术都利用了数据的连续性,比如AA
Virtual Shadow Maps
VSMs是一张巨大的贴图(16k x16k),将这张巨大的贴图切成一个个小的Pages,仅当屏幕中有像素需要某个Pages时,才分配加载这个Pages
于是出现了一个问题,要如何判定这个Pages被使用呢?
Clustered Deferred Shading
核心目标是剔除掉无用灯光
- 使用传统算法绘制GBuffer
- 分配Cluster(求切分后每一个Cluster的坐标)
- 找到唯一Cluster
- 分配灯光
- 着色
分配Cluster
根据连续性,若一个物体被某个灯光影响,其相邻的物体大概率也会被这个灯光影响
Cluster的本质就是将靠在一起的东西合并,光照计算时以Cluster为单位,而非Mesh/三角形。也就是说将这一组Mesh/三角形原子化(quantize)了
空间划分的方法有:
- 世界坐标Grid切分
- 数量过大,在远处存在浪费
- NDC空间按z均匀切分
- NDC非线性,近处Cluster过细,远处过粗
- View空间,按指数间隔切分深度
最后作者选择了View空间按指数间隔切分深度,根据屏幕Tiles坐标$(i,j)$和深度等级$k$,每一个Cluster将拥有坐标$(i,j,k)$,他们在z轴方向上的距离间隔为$h_k$
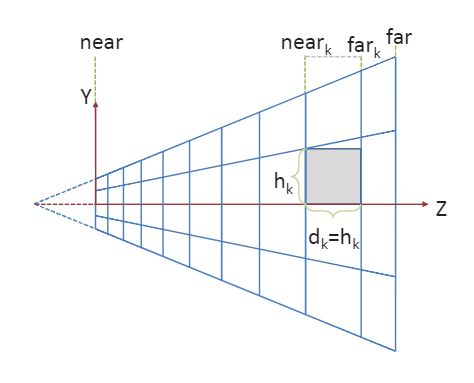
k是可以通过相机近平面、相机视角、该点深度和屏幕Tiles坐标求得
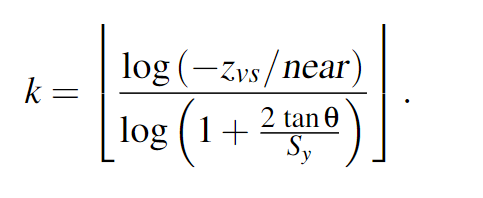
找到唯一Cluster
对每一个Tiles下的所有Cluster内物体进行排序
分配灯光
计算每一个Cluster受哪些光影响
在TBS中,我们可以直接遍历测试每一个Tiles和光源是否有覆盖,但这对于Cluster来说有些暴力了
- 每一帧根据Z值顺序,将相邻的灯光(相邻32个灯)的BV合并,构建BVH(bounding volume hierarchy)
- 使用深度优先算法做Cluster和灯光BV的相交测试
英伟达GPU对32叉树更友好,而且32叉树深度更小,可以减少分支数
这相较于Tiles Base有个好处是,当灯光特别特别多,均匀遍布在每一级深度中时,靠前的物体不需要再与靠后的灯光进行测试、着色(这是Tiles Base这种由最浅到最深构建的大BV无法做到的),能提升部分性能
着色
用传统方案做着色计算
作者的数据
我眼花了吗?作者对海量灯光的定义也太大了吧,这是12年的论文吧,同屏百万光源?手游项目同屏也就三四个点光吧
在灯光数量较少时(比如同屏灯光少于1024个???),性能不如Tiles Base
在灯光特别多时(比如同屏灯光1048576个!!!),性能显著强于Tiles Base
一点点想法
延迟渲染光照计算次数 = 屏幕像素数 x 灯光数量,为了进一步提高着色效率,我们要剔掉一部分灯光
利用连续性原理,若一个像素被某个灯光影响,那么这个像素相邻的像素也可能被灯光影响,于是我们将view切分为一个个恰当尺寸的Cluster,每个Cluster只做一次灯光可见性测试,Cluster内部都使用相同的灯光list
与Tiles Base比,Cluster不仅对屏幕空间进行切分,还对深度进行切分,这使得被切分的空间复杂度是稳定的,和视角无关
不过Cluster与灯光测试比Tiles Base复杂了,而且Cluster的数据量更多,于是作者又基于深度构建了灯光的BVH,加速两个BV的测试
不过我们引入了两个3D场景描述结构,还使用了更复杂的相交测试方法,结果灯光较少时性能还更差了。。。移动端这两年苹果才刚开始大力推TBDR,感觉还是Tiles Base更有性价比
参考
Tailor Your Apps for Apple GPUs and Tile-Based Deferred Rendering