强化学习与扩散模型
在不远的过去,强化学习被各种唱衰,环境难以模拟、算法难以泛化、激励难以设计、应用场景有限等等。很多人认为强化学习很酷,但就是“没用”。但随着LLM的兴起,RL可以帮助LLM实现对齐人类偏好、提升生成质量、低成本Post Train,RL瞬间成为了一种杀手级应用。最近一段时间,无论是LLM、Diffusion、具身智能,都开始搞RL了。
RL这种范式,在Diffusion训练上可能极具潜力,我最近打算使用RL训练Diffusion,以提升美学质量和图文对齐程度,于是从头开始学习RL
强化学习
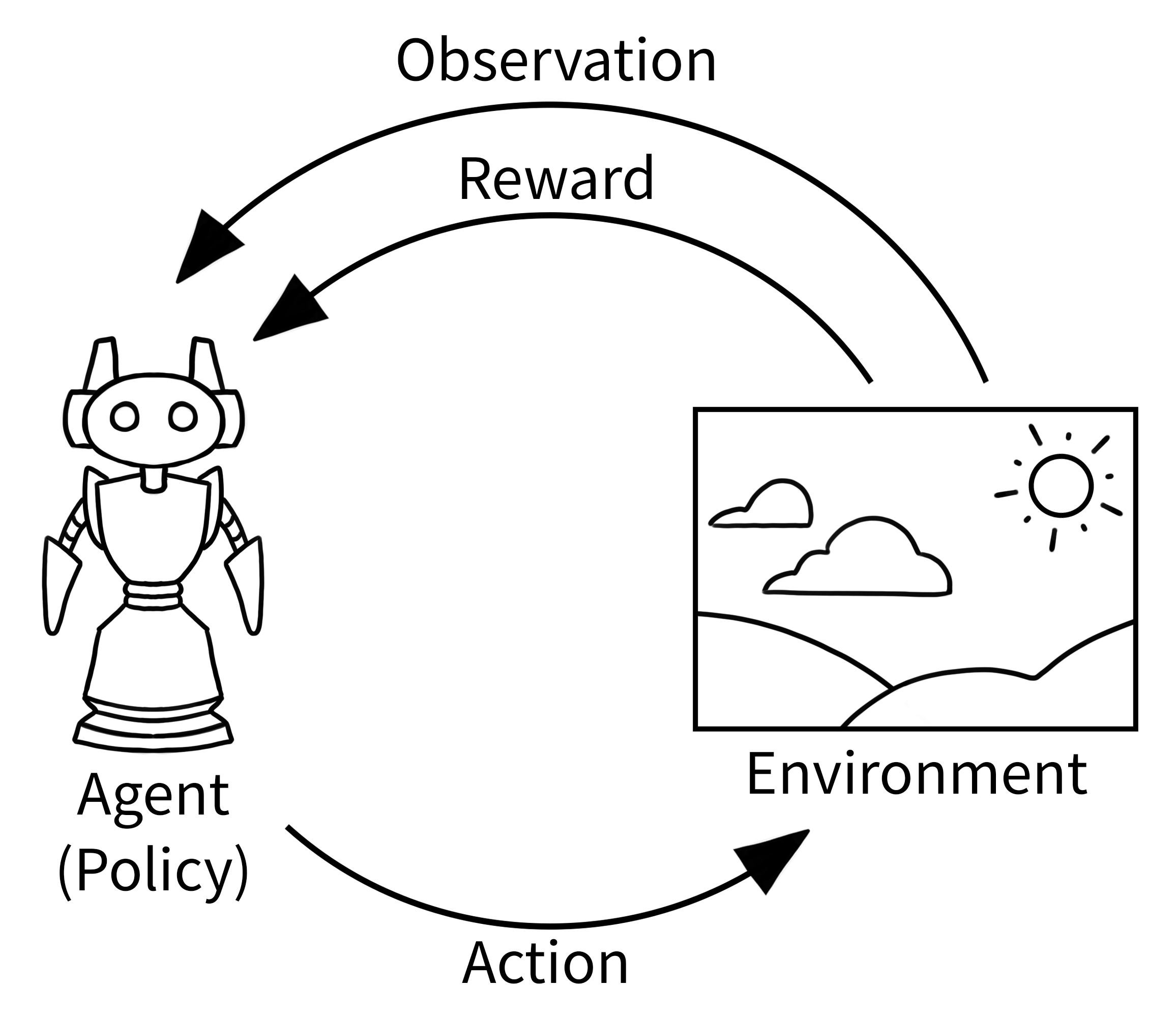
强化学习(reinforcement learning,RL)讨论的是智能体(agent)如何在环境中最大化奖励。智能体一直在与环境交互,智能体会评估当前状态,输出动作,获得奖励。
-
状态(State):在生成模型中可以定义为中间图像、latent
-
动作(Action):在生成模型中可以定义为预测噪声/方向
-
策略(Policy):扩散模型的参数
- on-policy:边做边学(学下棋时每一步都有老师来评价你下的好不好)
- off-policy:看别人怎么玩(学下棋时看别人的棋谱)
-
环境(Environment)
-
奖励(Reward)
- model free:没有显式的状态转移概率和奖励函数
- model base:有显示的可学习的状态转移函数和奖励模型(Reward model)
传统RL算法
Q-Learning
一种off-policy方法
Q表格是一张已经训练好的表格,行是状态数,列表示在该状态下该动作的平均总奖励,形如
| 动作1 | 动作2 | |
|---|---|---|
| 状态1 | 0 | -90 |
| 状态2 | 0 | 10 |
表格型方法:通过查Q表格,我们就可以判断某个状态应该使用什么动作。训练的过程就是将一张空的Q表格填满,用蒙特卡洛采样的方式更新Q表格
DQN
Deep Q-Network
Q-Learning的深度学习版本,用神经网络去模拟Q表格
策略梯度
Policy Gradient
策略(policy)是智能体的决策规则,是智能体在状态 $s$ 下采取行动 $a$ 的概率,由参数 $\theta$ 控制
$$
\pi_\theta(a|s)
$$
策略是参数化的 $\pi_\theta$,将长期奖励目标视为 $\theta$ 的函数,用梯度上升的方法优化它
直观含义是:
- 如果一个动作回报高,则增加这个动作的概率
- 如果一个动作回报低,则降低这个动作的概率
根据学习策略和环境策略,可以分为
- 同策略(on-policy):学习的策略和与环境交互的策略是同一个,如PPO
- 异策略(off-policy):学习的策略和与环境交互的策略可以不同,如Q-Learning、DQN
以学下棋为例,如果一个人每下一步棋,就有老师给他打分,这个棋局是自己下出来的,就是同策略。而如果是观察他人下棋,老师告诉你哪一步是好棋/坏棋,这就是异策略
PPO
近端策略优化(proximal policy optimization,PPO),目标是做保守的策略更新,用替换目标(surrogate objective)衡量新策略相对旧策略的改进,并用clipping或KL惩罚来防止更新幅度过大,兼顾学习速度和稳定性
RM负责对策略进行打分
以学下棋为例:
采样:下棋
打分:老师评价下的好不好
比较新旧策略:学生修改下法,并评估新旧策略变化 $r = \frac{\pi_{new}}{\pi_{old}}$
clipping:从“当头炮”改为“马先跳”,概率改动太大,舍弃这次
优势函数:老师不仅告诉学生这一步走的好/坏,还要告诉这步棋比平均水准高多少
更新策略:根据优势函数和概率比 $r$ ,微调自己的策略
DPO
没有显式的RM,而是人工构造成对数据,将对齐问题转化为监督学习问题。在小规模数据上比较方便,不需要RM和复杂的训练流程,但是数据量增大后成本过高不可行
GRPO
组相对策略优化(Group Relative Policy Optimization,GRPO),最早源自DeepSeek,用组内相对分数(这个相对分数可以来自Reward Model)来构造优势,省去价值(Critic)网络
以学下棋为例:
对于一个局面,列举了多种下法,如走炮、跳马、拱卒
老师评价相对分数,如走炮最好,然后是跳马,最差是拱卒
构建相对优势(走炮不需要知道自己具体多少分,只需要知道比平均值高,是正的,而拱卒的优势是负的)
用概率比 $r = \frac{\pi_{new}}{\pi_{old}}$ 更新策略
Reward Model
Reward Model根据输入输出类别,可以分为
- pointwise:输入一张图,输出标量分数
- pairwise:输入一组图片,输出相对分数
根据模型架构,可以分为
-
分类器,输入数据输出标量数字/好坏
-
CLIP + MLP:CLIP将文本prompt和图像提取feature,用MLP打分
-
VLM + MLP:VLM将文本prompt和图像提取feature,用MLP打分
-
-
生成式VLM:将评价过程视为一个生成任务,先进行一段CoT分析,再给出分数/好坏
-
LLM as Judge:用一个超强的LLM作为Reward Model进行打分
- 位置偏见,模型可能会偏向认为第一/二个出现的回答更好,可以通过交换位置多测试克服
- 长度偏见,模型可能会认为写的长的回答更好
- 自我偏见,模型可能会更喜欢自己模型风格的内容(比如让GPT去评价一组由GPT、Gemini、DeepSeek生成的内容,GPT更喜欢GPT风格的内容)
| 工作 | 模型架构 | 开源数据集 | 数据量 |
|---|---|---|---|
| HPSv2 | CLIP + MLP | ymhao/HPDv2 | 798k对 |
| PickScore | CLIP + MLP | yuvalkirstain/PickaPic-rankings | 150k对 |
| ImageReward | BLIP + MLP | zai-org/ImageRewardDB | 137k对 |
| HPSv3 | VLM + MLP | MizzenAI/HPDv3 | 1M 对 |
| UnifiedReward | VLM | CodeGoat24/EvalMuse,CodeGoat24/HPD,CodeGoat24/OIP | 35k对 |
| UnifiedReward CoT | VLM | CodeGoat24/ImageGen-CoT-Reward-5K | 5k对 |
| RewardDance | VLM |
动机
训练Diffusion时,目标常常是MSE(噪声重建损失)和最大似然(log-likehood),但是这些训练目标并不一定符合人类审美
- 将人类偏好转化为可优化的信号
- 提供可用于RL的Reward
- 解决不可微指标的问题(如语义一致性、美学质量、肢体合理性)
理论上收集满足人类偏好的数据进行SFT,也可以用于优化模型,但是大规模收集人类反馈的成本过高。在有限量的偏好数据中训练Reward Model,在用RM做视觉模型的对齐,效率更高
挑战
- 奖励稀疏
- 模式坍塌
- Reward Hacking:Diffusion模型学会了最大化奖励函数,但没能真的学会你想要的能力,而是利用奖励函数的漏洞来作弊,取巧没学到真东西
一个经典的Reward Hacking,如果我想要模型生成一个梵高风格的画,结果一些模型生成了带有”梵高“签名的普通作品,这些普通作品可能会得到更高的Reward分数,导致模型没能成功学会生成梵高风格的画,而是学会生成梵高签名
HPSv2
《Human Preference Score v2: A Solid Benchmark for Evaluating Human Preferences of Text-to-Image Synthesis》2023.9
PickScore
《Pick-a-Pic: An Open Dataset of User Preferences for Text-to-Image Generation》2023.11
ImageReward
《ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation》2023.12
动机
扩散模型在保真度和多样性上取得非常好的成绩,但是与人类偏好还是有差异
- 文本图像对齐:无法准确捕捉提示词中的数量、属性、空间关系(生成错误数量多猫、错误位置的猫)
- 人体结构畸形:肢体扭曲、多余、融合、残缺(多/少手指)
- 审美偏差:生成结果偏离主流人类审美(如诡异的光影、畸形的脸、廉价的卡通感、AI感)
- 毒性和偏见(如NSFW)
作者希望将RLHF(reinforcement learning from human feedback)的范式引入到视觉生成模型领域
创新点
- 基于BLIP的Reward模型
- 搭建一套偏好数据标注、处理流程
- ReFL训练Diffusion
数据
-
从DiffusionDB中挑选真实用户prompt,基于图算法和大模型判断prompt相似度,保证了prompt的多样性
-
人工标注了137k pair数据
标注流程:
- 提示词标注
- 将prompt进行预分类,如人物肖像类、风景类、动物类、静物 / 食品类、抽象艺术类
- 问题识别,剔除模糊不清、含有有害内容的数据
- 文本图像评分
- Alignment 对齐度
- Fidelity 逼真度
- Harmlessness 无害性
- 图像排序
Reward模型架构
基于BLIP,将图片和文本提取feature,用cross attention合并,用MLP输出分数
HPSv3
《HPSv3: Towards Wide-Spectrum Human Preference Score》2025.8
Reward模型架构
VLM提取文本和图像feature,MLP打分
Loss设计
Loss设计为二选一的偏好建模,希望可以把偏好的样本分数提高,次偏样本分数压低
作者提供了两个殊途同归的Loss,最小化KL散度和最大化BT似然
KL-divergence
相对熵/KL散度,用于衡量两个概率分布之间差距的度量
Bradley–Terry
Bradley–Terry 模型是一种用于建模成对比较偏好概率的经典统计模型
它假设每个样本 $i$ 有一个潜在的“实力”或“得分” $s_i$,然后用 softmax 形式建模偏好概率:
$$
P(i \succ j) = \frac{\exp(s_i)}{\exp(s_i) + \exp(s_j)}=\mathrm{sigmoid}(s_i-s_j)
$$
$$
\mathcal{L}{BT} = - \log P\theta(i \succ j)
$$
UnifiedReward
《Unified Reward Model for Multimodal Understanding and Generation》2025.3
动机
- 过去的RM往往是单一维度
- 视频和图像生成是有联系的,视频RM和图像RM应该可以统一
创新点
支持图像生成、图像理解、视频生成、视频理解的多模态RM
Prompt
Pairwise Image Gen
You are given a text caption and two generated images based on that caption. Your task is to evaluate and compare these images based on two key criteria: |
数据
- CodeGoat24/EvalMuse:pairwise 图片谁比谁好
- CodeGoat24/HPD:pairwise 图片谁比谁好
- CodeGoat24/OIP:pairwise 图片谁比谁好
- CodeGoat24/LLaVA-Critic-113k:
OneReward
《OneReward: Unified Mask-Guided Image Generation via Multi-Task Human Preference Learning》2025.8
UnifiedReward Think
《Unified Multimodal Chain-of-Thought Reward Model through Reinforcement Fine-Tuning》2025.8
训练流程
- 模型使用UnifiedReward为basemodel,经过预训练,有初始的图像好坏判断能力
- 视频、图像的pairwise比较
- 视频、图像的pointwise得到绝对分数
- 使用少量(5k)CoT格式的数据训练,让模型学会输出CoT结构
- 拒绝采样:用CoT模型大量清洗GT数据,得到大量CoT数据
- 挑出和GT一致的CoT数据,进行大规模训练
- GRPO:准备大量图片和问题,让模型进行GRPO
Prompt
Q:
Which of the following images is better? Text Caption: [{caption}] |
A:
<think> |
数据
- CodeGoat24/ImageGen-CoT-Reward-5K:pairwise CoT 图片谁比谁好,XML格式
Reward Dance
《RewardDance: Reward Scaling in Visual Generation》2025.9
动机:构建一个统一的、可缩放的的RM
创新点:
-
训练一个VLM,输入两张图片和prompt,输出yes/no,判断第一张图是否更好
- 作者还验证了RM和RLFT的scaling up,在不同参数量的InternVL上做实验,参数量越大效果越好
-
奖励分数设置为VLM预测yes的概率
-
相较于CLIP等模型,VLM更容易进行scale up,可以使用1B~26B的模型
-
可以引入CoT,除了简单的yes/no,还可以额外生成reason,以提高RM的可解释性
Reward Dance是先判断yes/no,再跟CoT数据,这样在实际应用时确实可以通过控制max nexttoken,提高RM的效率,但这是否会导致CoT只是对初次判断的找补、解释?
RM构建
CoT 数据构建
system_prompt = '''You will act as a professional image quality evaluator. |
RM测评
- In-Domain:从数据集中挑选2500对,这部分数据不会送进训练
- Out-Of-Domain:从开源测评集中挑选4000对
RLFT测评
What Makes a Reward Model a Good Teacher?
《What Makes a Reward Model a Good Teacher? An Optimization Perspective》2025.9
RLHF的关键在于Reward Model质量,作者认为衡量一个RM的有效性,不仅靠准确率,还要能产生较大的方差
作者认为,如果一个模型高正确率低方差,输出的分数尽管排名是对的,但是分差太小,学生学不到做什么能得高分/低分,进步非常缓慢
所以这里的RM是一个基于绝对分数的RM,对于pair compare的模型,这个结论还适用吗?
答:适用,输出yes/no的模型,其nexttoken预测也是生成一个含有yes/no的logits,内置了一个概率分布
EditScore
《EditScore: Unlocking Online RL for Image Editing via High-Fidelity Reward Modeling》2025.9
一个pointwise的编辑模型reward,输入编辑指令、编辑前后图像,输出CoT和编辑分数(编辑成功率、过度编辑程度)
RL方法
Diffusion DPO
《Diffusion Model Alignment Using Direct Preference Optimization》2023.11
23年年末,基于RLHF微调LLM已经取得了巨大进步,但微调Diffusion仍为得到足够探索
Diffusion-DPO使用最简单的DPO方法,构造直接偏好对(85.1对) ,进行微调模型(这里指SDXL)
策略梯度:RL的目的是给定输入,若输出 $x$ 符合人类偏好的,则增加生成 $x$ 的概率,反之则降低概率。
相较于监督学习,模型学习输入的数据,RL会让模型进行探索(比如让模型生成一串文本、生成一张图片),然后根据Reward Model动态决定概率的升降。
而对于DPO而言,我们离线进行了探索(使用参考模型生成大量数据),人工/基于RM进行标注,让模型学习概率的升降
引入DPO的困难
在LLM中,模型生成某段文本序列的概率就是每个单词概率的乘积。但在Diffusion中,生成一个图 $x_0$ 需要经过许多步去噪得到,从原始噪声到最终图像理论上存在无数条路径,于是我们无法计算出Diffusion生成某张特定图像的概率 $p_{\theta}(x_0 | c)$。
为了绕开这个问题,作者不去计算生成特定图像 $x_0$ 的概率,而是去计算产生这一整条去噪路径 $x_0 … x_T$ 的可能性。在扩散模型中计算 $p(x_{t-1}|x_t)$ 非常简单,我们直接将从0到T所有的 $p(x_{t-1}|x_t)$ 相乘,就得到了 $p(x_{0:T})$
利用ELBO(证据下界),将整个生成链上的奖励定义为 $R(c,x_{0:T})$ ,优化 $p(x_0)$ 的下界等价于优化每一步的去噪误差,将图像奖励定义为:
$$
r(c, x_0) = E_{p_\theta(x_{1:T}|x_0, c)} [R(c, x_{0:T})]
$$
作者还引入了KL 散度正则化项,防止模型为了得高分而走极端,导致模式崩溃
loss定义为 “新模型生成好图路径的概率比旧模型高了多少” 减去 “新模型生成好图路径的概率比旧模型高了多少”:
$$
\mathcal{L}{\text{DPO-Diffusion}}(\theta) = -E{(x_0^w, x_0^l) \sim \mathcal{D}} \log \sigma \left( \beta E_{\substack{x_{1:T}^w \sim p_\theta \ x_{1:T}^l \sim p_\theta}} \left[ \log \frac{p_\theta(x_{0:T}^w)}{p_{\text{ref}}(x_{0:T}^w)} - \log \frac{p_\theta(x_{0:T}^l)}{p_{\text{ref}}(x_{0:T}^l)} \right] \right)
$$
- $p_{ref}(x)$:当前模型未微调前,生成这张图的概率
- $p_\theta(x)$:模型微调后,生成这张图的概率
- $\sigma$:Sigmoid函数,将差异值转为0~1的概率
- $-\log(p)$:模型判断对了(p接近1),损失接近0,判断错了(p接近0),损失无穷大,模型受到处罚
对高斯分布取对数,会得到一个二次方程(抛物线)
$$
p(x) = \frac{1}{\sqrt{2\pi\sigma^2}} \cdot e^{-\frac{(x - \mu)^2}{2\sigma^2}}
$$
$$
\log p(x) = \underbrace{\log(\frac{1}{\sqrt{2\pi\sigma^2}})}{\text{常数 C}} + \underbrace{\log(e^{-\frac{(x - \mu)^2}{2\sigma^2}})}{\text{指数消失}}
$$
$$
\log p(x) = C - \frac{1}{2\sigma^2}(x - \mu)^2
$$
经过化简,我们发现DPO的loss本质上是两个均方误差(MSE)相减
$$
Loss = -\log \sigma \left( \beta \left[ (\text{Ref误差}^w - \text{Model误差}^w) - (\text{Ref误差}^l - \text{Model误差}^l) \right] \right)
$$
# 模型预测结果,计算MSE,得到 model_losses_w - model_losses_l |
ImageReward
《ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation》2023.12
ReFL
0 --> t --> 0
- 按正常流程生成loss、更新LDM模型参数
- 随机挑选中后期的timestep(30~40)
- 0到 $t$ 不反传梯度,只前向生成,从图像开始得到一个中间噪声
- 在第 $t$ 步,开启梯度,从 $x_t$ 开始不断反向去噪得到潜变量 $x_0$,并解码出图像 $z_i$
- 将prompt和 $z_i$ 输入到reward模型中,得到reward分数
- 根据reward分数更新LDM模型参数
$$
\hat{x}_0 = \frac{x_t - \sqrt{1 - \bar{\alpha}t},\hat{\epsilon}\theta(x_t, y)}{\sqrt{\bar{\alpha}_t}}
$$
Flow-GRPO
《Flow-GRPO: Training Flow Matching Models via Online RL》2025.7
动机
- 基于FlowMatching的图像生成模型(如Flux、SD3.5)占据主导地位,但仍在在复杂组合场景(如精确物体计数、空间关系和属性绑定)以及文本渲染上表现很差。
- online RL 在LLM上取得了巨大成功
- online RL 无法直接用于FlowMatching模型
创新点
将FlowMatching的ODE转为等价的SDE,引入随机性,以支持RL探索
测评集
- GenEval(组合图像生成)
- OCR(文字渲染)
- PickScore(人类偏好对齐)
- DrawBench、DeQA、ImageReward(美学)
- CLIP
Pref-GRPO
《Pref-GRPO: Pairwise Preference Reward-Based GRPO for Stable Text-to-Image Reinforcement Learning》2025.8
DiffusionNFT
《DiffusionNFT: Online Diffusion Reinforcement with Forward Process》
动机
提出一种新的RL范式,不在反向过程,而是直接在前向扩散过程上执行策略优化,以克服GRPO的种种问题
GRPO RL的问题
过去的GRPO风格的diffusion RL存在很多问题
前向不一致
forward inconsistency
扩散模型有前向扩散和反向生成两个过程,而GRPO只关注反向采样过程,使用了和前向过程不一样的噪声调度、时间分布、损失函数,训练的模型轨迹不再是原来前向扩散的逆过程
当前向不一致发生后,模型的每个反向过程更像是独立的高斯采样,而非真正的去噪声,最终退化为高斯噪声串接(cascaded Gaussians)。
求解器限制
Solver restriction
传统扩散模型的Loss中包含随机项,导致Loss和采样器是强绑定的,如果更换采样器,理论一致性就会破坏,造成数据偏移、输出失真
更高阶的求解器或者ODE求解器往往在采样效率和轨迹预测上有优势,但是由于求解器限制我们不能直接替换这些求解器
CFG
使用CFG的模型在训练和推理时需要两次前向计算(有条件和无条件),导致计算和内存开销翻倍
$$
\epsilon_\text{CFG} = \epsilon_\text{uncond} + w \cdot (\epsilon_\text{cond} - \epsilon_\text{uncond})
$$
目前的GRPO RL依赖于CFG,为了提升效率需要移除这部分
负感知微调
优化方向
在Online RL中,将数据拆分为两个子集:正面和负面,其概率为
$$
\pi^+ > \pi_{old} > \pi^-
$$
我们希望优化方向可以同时用到正面和负面数据
如下图,假设我们后续要学的优化方向是 $v_\theta$ ,当前的速度场为 $v_{old}$ ,由训练数据 $x_0$ 得到的速度为 $v$
隐式正策略
$$
v^+= (1 - \beta)v_{\rm old} + \beta v_\theta
$$
隐式负策略:
$$
v^- = (1+\beta)v_{\rm old} - \beta v_\theta
$$
$v^+$ 和 $v^-$ 均与 $\theta$ 有关
由于正负策略均为优化方向和当前速度的组合,所以正负策略可以在同一方向上
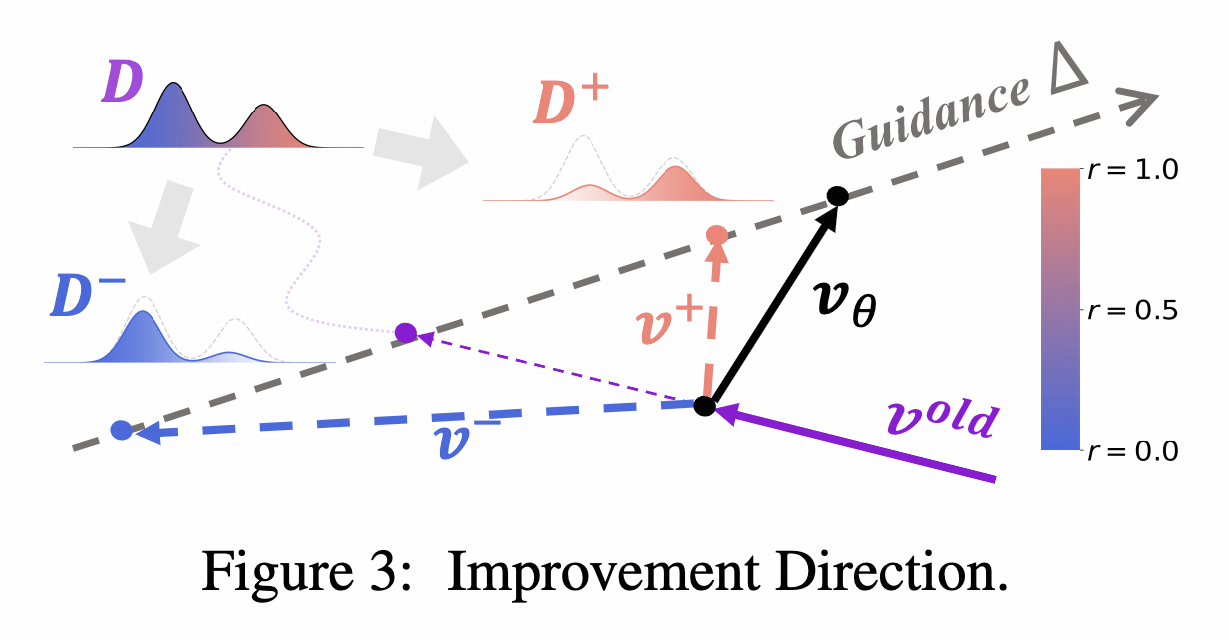
最终的loss为:
$$
\mathcal{L}(\theta) = \mathbb{E}_{c, x_0, t} \left[r | v^+ - v |^2 + (1 - r) | v^- - v |^2 \right]
$$
通过 $v$ 调整 $\theta$
策略优化
$$
v_\theta ^* = v_{\rm old} + \frac{2}{\beta} \Delta
$$
优势
- 前向一致性
- 求解器灵活
- 隐式引导集成(无CFG)
- 无似然表述