AI 常用术语
记录一些AI常用术语
机器学习
AGI(通用人工智能):能像人一样在多数认知任务上通用地学习、推理、适应与创造
ASI(超级人工智能):在几乎所有领域都远超人类智能的系统
监督学习
Supervised Learning
目标:从标记好的数据中学习输入到输出的映射,以泛化到新数据。
- 回归(Regression):预测连续型变量的值,如股票价格预测。
- 分类(Classification):预测离散型变量的类别,如图像分类。
- 偏好学习(Preference Learning):预测偏好顺序或选择,如电影排名。
无监督学习
Unsupervised Learning
目标:从无标签的数据中提取特征,发现数据的内在结构。
- 聚类(Clustering):将数据划分为不同的组别,使得组内的相似性最大化,如客户细分。
- 降维(Dimensionality Reduction):减少数据的维度,同时保留重要信息,如主成分分析(PCA)。
- 异常检测:识别数据中的异常点或异常模式。
- 自监督(Self-Supervised Learning):表示学习,利用数据本身的内在结构或关系来生成标签,进行学习
强化学习
Reinforcement Learning,RL
目标:通过与环境的交互,学习最优策略以最大化累积奖励。
核心概念:
- 智能体(Agent):执行动作的实体,如自动驾驶汽车。
- 环境(Environment):智能体所处的外部世界。
- 状态(State):智能体当前的状况,如位置、速度。
- 动作(Action):智能体可以执行的操作,如加速、刹车。
- 策略(Policy):根据状态决定动作的规则。
- 奖励(Reward):对智能体行为的反馈,用于指导学习。
马尔可夫决策过程
过程(Process):一个随着时间变化的随机变量序列。如每天的股票价格、每天的天气情况
马尔可夫性:未来仅依赖于当前,而不依赖过去
$$
P(s_{t+1},|,s_t, s_{t-1}, \dots, s_0) = P(s_{t+1},|,s_t)
$$
马尔可夫链(Markov Chain):一种满足马尔可夫性的随机过程
马尔可夫过程(Markov Process):马尔可夫链的形式化定义
$$
\langle S, P \rangle
$$
-
$S$:状态空间
-
$P$:状态转移概率矩阵
马尔可夫奖励过程(Markov Reward Process, MRP):在MP上加入奖励信号
$$
\langle S, P, R, \gamma \rangle
$$
- $R(s)$:在状态 $s$ 下得到的期望奖励
- $\gamma \in [0,1]$:折扣因子,控制未来奖励的重要性
马尔可夫决策过程 (Markov Decision Process, MDP),在MRP中引入动作,智能体可以通过策略来影响环境演化
$$
\langle S, A, P, R, \gamma \rangle
$$
- $A$:动作空间
生成模型
目标:生成与真实数据相似的新数据样本。
-
无条件生成(Unconditional Generation):如无条件生成蝴蝶图片。
-
条件生成(Conditional Generation):如文本到图像生成(T2I)。
常见模型:
-
GAN(Generative Adversarial Network):通过生成器和判别器的对抗训练生成数据。
-
VAE(Variational Autoencoder):在自编码器(AE)基础上对潜在空间分布建模,使得潜在空间中充满了有效数据,通过在潜在空间采样,即可生成数据。
- Conditional VAE:引入标注信息,实现条件生成。
-
VQVAE(Vector Quantized VAE):将潜在空间离散化,解决后验崩塌问题。
-
自回归模型(Autoregressive Model,AR):利用时间序列的过去值预测未来值(next token),逐步生成数据。
- 视觉自回归模型(Visual AutoRegressive modeling,VAR),在AR模型上引入了multi-scale, coarse-to-fine生成图像,每一步模型用低分辨率作为条件,预测更高分辨率的输出
-
扩散模型(Diffusion Models):通过前向加噪和反向去噪的过程生成数据。
- LDM(Latent Diffusion Model):在潜在空间进行扩散,降低计算成本。
- DiT(Diffusion Transformer):使用Transformer替代UNet,进行噪声的预测。
VAE、VQVAE现在往往并不会用来做数据生成,而是作为LDM、VLM的编解码器
其他任务
- 时序预测
- 推荐系统
术语解释
SOTA(State of the Art)
表示在某个特定领域中的最好成果、最佳实践。
良定义(Well-Defined)
要求:
- 明确性:明确指出所定义对象的范围和特征。
- 一致性:定义不能自相矛盾。
- 完备性:定义要包含足够的信息,使得人们可以通过定义判断一个对象是否属于定义的范围。
- 无歧义性:定义要避免使用含糊不清、多义词。
量化指标
召回率
Recall
衡量模型对正例的识别能力(样本中的正例有多少被预测正确了)
$$
\text{Recall} = \frac{\text{TP}}{\text{TP} + \text{FN}}
$$
- TP(True Positive):预测为正例且实际为正例的数量。
- FN(False Negative):预测为负例但实际为正例的数量
精确率
Precision
衡量模型预测为正的样本中真正的正样本比例(预测为正的样本中有多少是真正的正样本)
$$
\text{Precision} = \frac{\text{TP}}{\text{TP} + \text{FP}}
$$
- FP(False Positive):预测为正例但实际为负例的数量。
FID
Fréchet Inception Distance
评估生成式模型生成样本的质量,通过计算生成样本与真实样本在特征空间中的分布差异
PSNR
Peak Signal-to-Noise Ratio
峰值信噪比,衡量图像或信号的重建质量,良好的8bit图像psnr一般在20~30,越大越好
mse = np.mean((image1 - image2) ** 2) |
PSNR低,说明模型生成的细节丢失多,还原差
SSIM
结构相似性指标,用于衡量图像的结构和纹理相似性,越大越好
Perceptual Similarity
感知相似度,用于衡量两张图像在人类视觉感知上有多么相似
实验方法
消融实验
Ablation Study
确定一个条件或参数对结果的影响程度,通过去除或修改模型的某种组成,观察其对模型性能的影响
交叉验证
Cross-Validation
评估模型的泛化能力,通过将数据集划分为多个子集,轮流使用其中一个子集作为测试集,其余作为训练集
超参数调优
Hyperparameter Tuning
优化模型的超参数,以获得最佳性能
from scratch
从零开始,表示不使用预训练模型,而是从零开始训练
神经网络
BNDE
B:Batch,批次大小
N:序列长度
D:Dim,特征纬度
E:Embed,嵌入纬度
BCTHW
- B 表示批量维度(batch)
- C 表示通道维度(channel)
- T 表示时序维度(time)
- H 表示高度维度(height)
- W 表示宽度维度(width)
前向传播
做预测/推理的过程,输入数据到神经网络,经过逐层的计算,输出最终结果的过程
反向传播
根据梯度下降更新模型参数的过程。根据链式法则计算梯度,这个过程是从后向前传递,所以叫反向传播
激活函数
由于”线性函数的线性函数,还是一个线性函数“,而对神经元进行加权求和是一个线性操作,为了让模型能表示一些非线性的东西,我们需要激活函数
$$
a=f(z)
$$
- $f$:激活函数,任意一个非线性函数,常见为ReLU、Sigmoid
- $z$:上一神经元的加权求和结果
神经网络通过反向传播来训练,激活函数必须是可微的,或者几乎处处可微(ReLU在0点不可导,但在其他地方可导)
次梯度
subgradient
ReLU是一种不可微但凸的函数。
- 不可微:因为在0点处中断了,不可导
- 凸函数:在函数上任意两点连成的线段,一定在函数图形的上方的函数
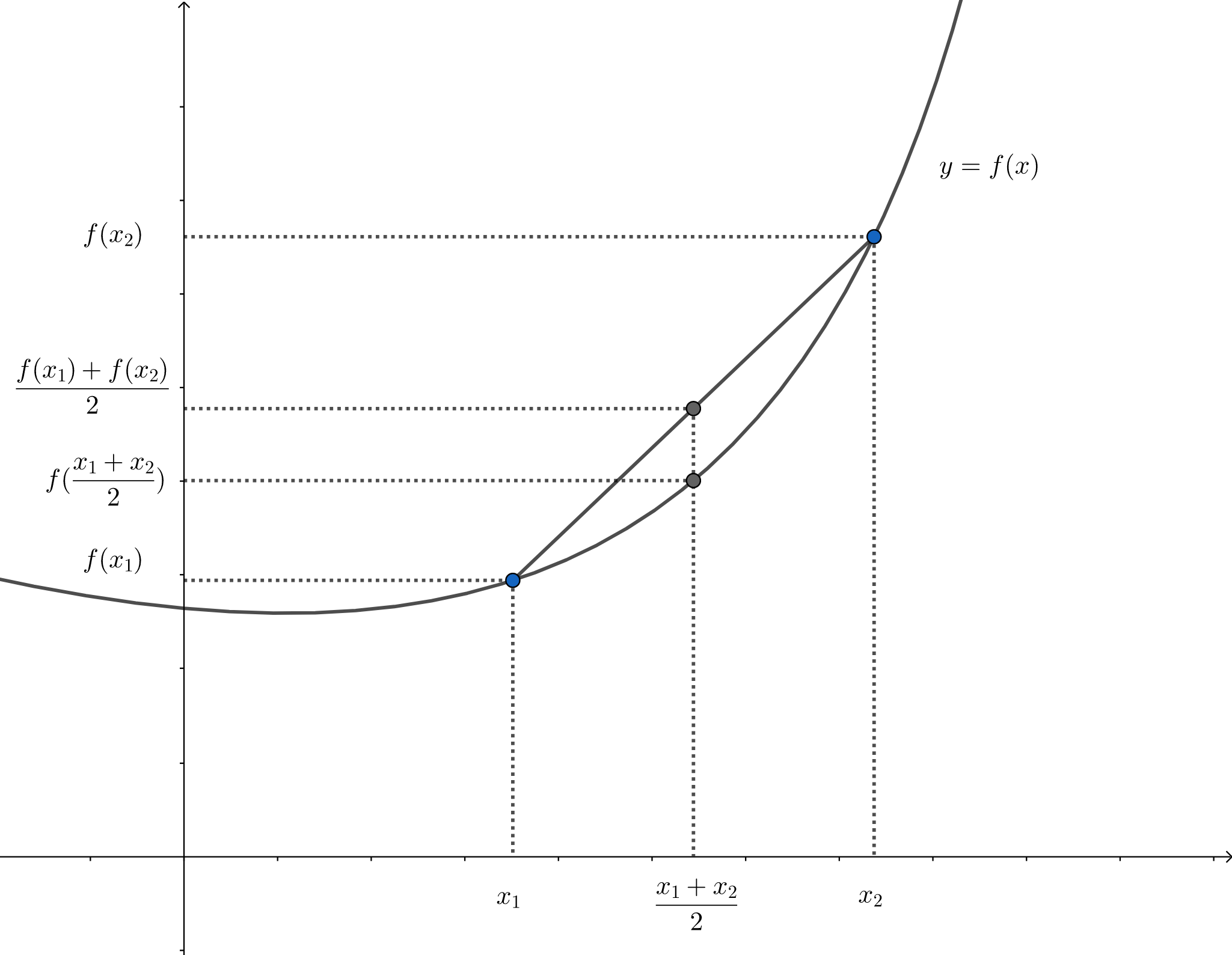
对于这种函数,我们可以用次梯度来近似梯度,对于ReLU,我们可以在0点处得到一组扇面,扇面内点直线均可以作为次梯度。在深度学习中,我们在扇面中随机取一个斜率作为梯度来优化
MLP
Multilayer Perceptron
多层感知器,一种最简单的前馈神经网络
前馈(Feedforward)是一种控制机制,通过在系统受到干扰之前就采取行动来预测和补偿干扰的影响,具有预测性
前馈的反义词是反馈,在生物学中很常见
CNN
Convolutional Neural Network,卷积神经网络
由卷积层、全连接层、池化层等部分组成
CNN模型结构中,卷积带来了局部性,使用相同卷积核带来了平移等变性,这些性质被称为先验知识(prior knowledge)
全连接层
该层每个神经元,都与上一层所有神经元相连。参数量会非常巨大,mxn
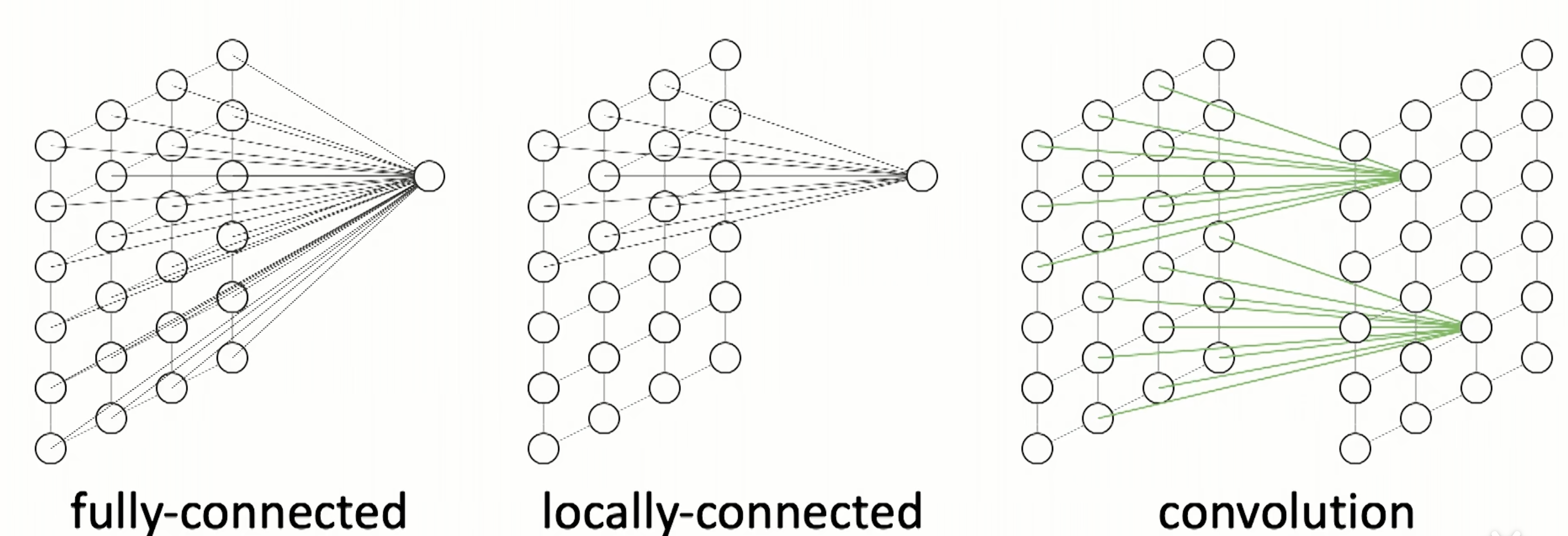
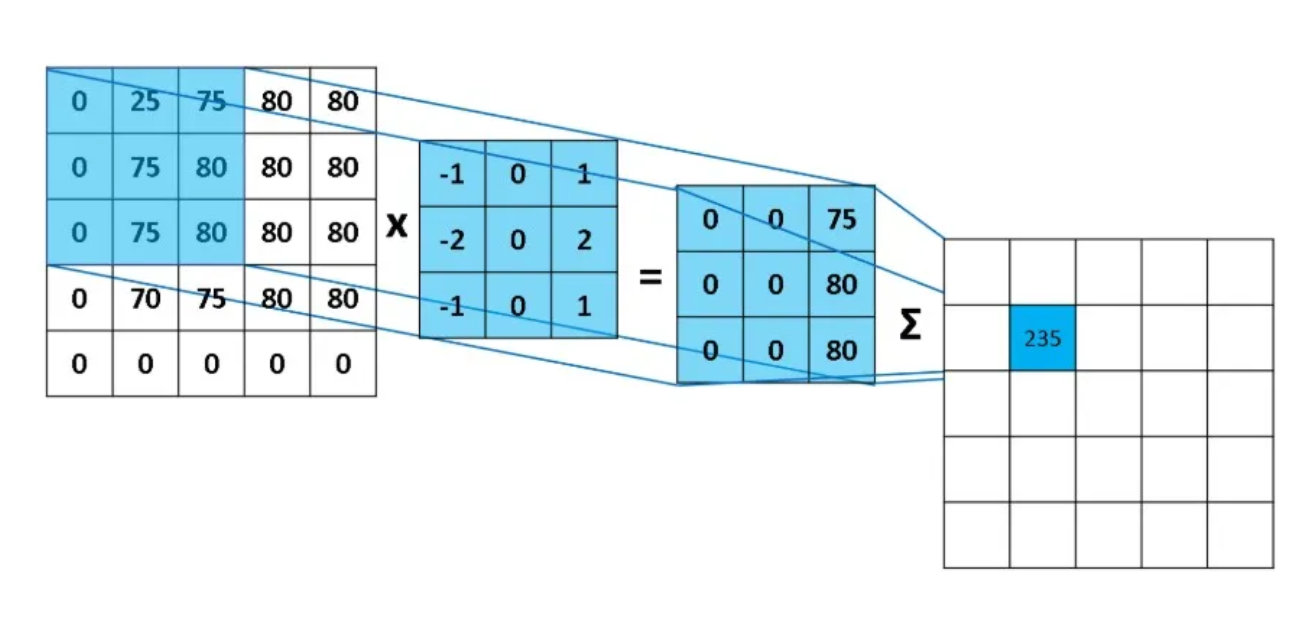
卷积层
卷积层=局部连接+空间权重共享
局部连接:卷积层的每个神经元只与输入数据的局部区域相连,而不是与整个输入数据相连(相邻像素相关性通常比远距离的像素大)
空间权重共享:使用相同的卷积权重在不同位置提取相同特征(图像的底层特征,如边缘,通常与具体位置无关)
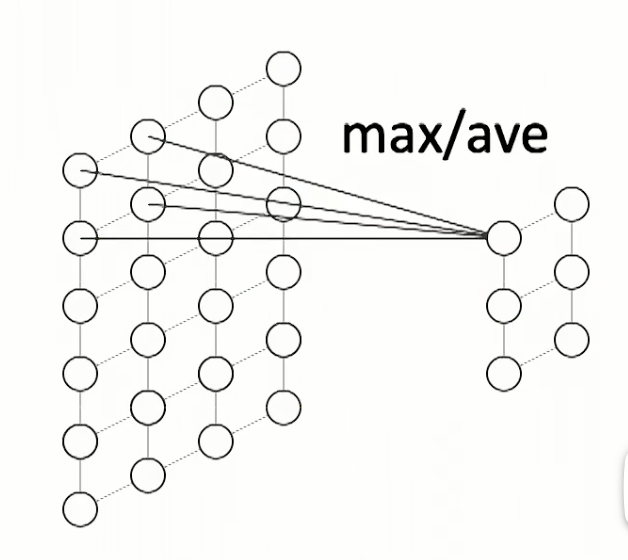
池化层
使用一个滑动窗口在神经元间操作,如求最大值(最大池化),求平均值(平均池化)
池化层的目的是降采样,生成一个尺寸更小的特征图
池化层可以实现局部不变性:窗口内发生微小抖动,但仍旧可以得到相同/相似的特征表示
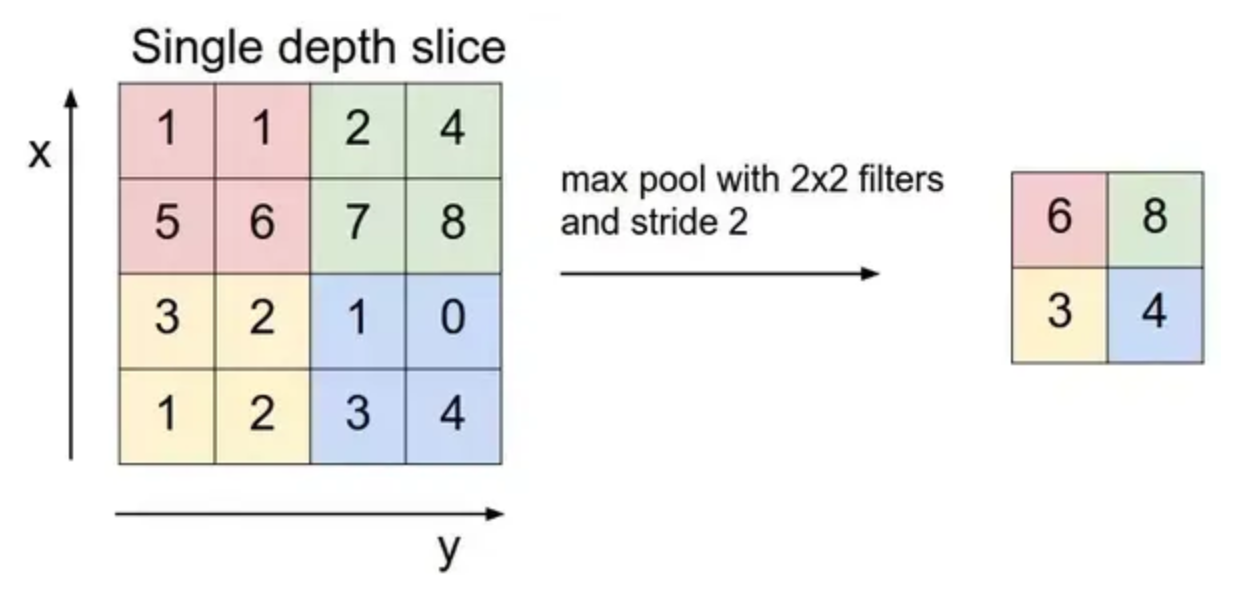
RNN
Recurrent Neural Network,循环神经网络,参考Understanding-LSTMs
$$
y_t=f(y_{t-1}, x_t)
$$
能够处理序列变化的数据(能够理解同一数据在不同上下文中含义不同)
由于RNN依赖先前的输出结果(RNN不是前馈的),因此对GPU并不友好
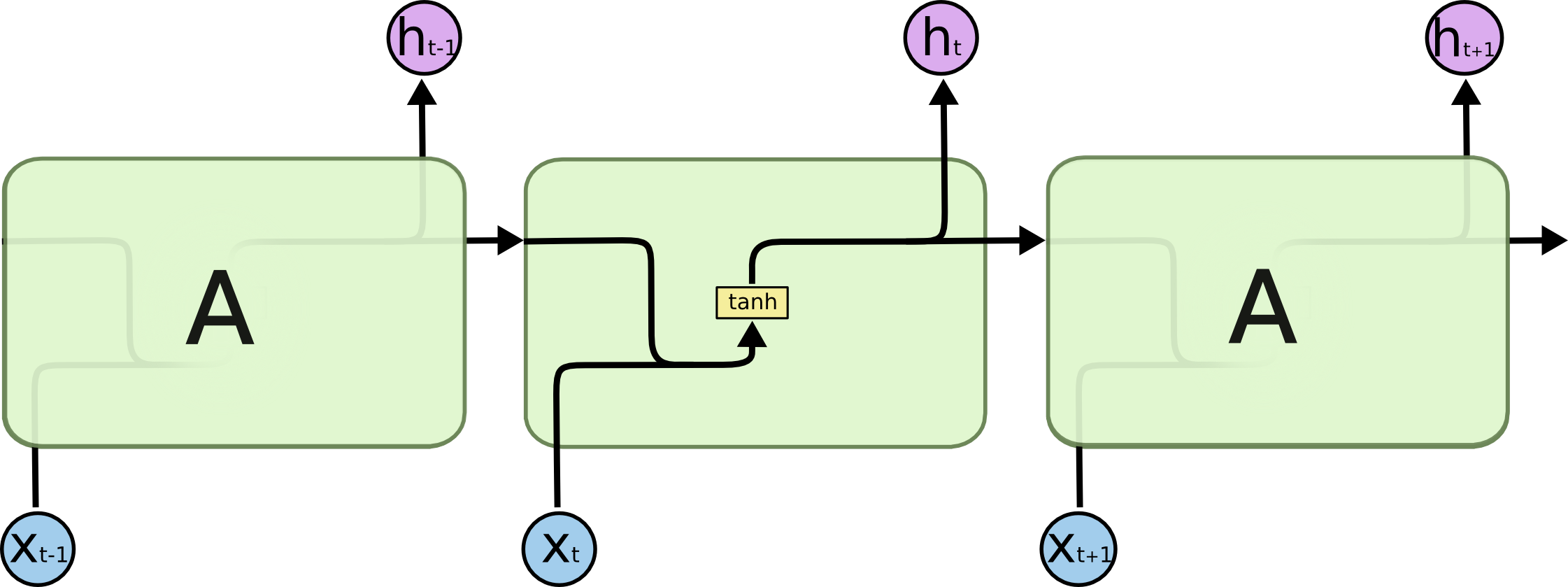
LSTM
长短期记忆,比RNN在长序列中表现更好
RNN的一个问题是,他无法从先前的关键词中有选择地提取重要信息
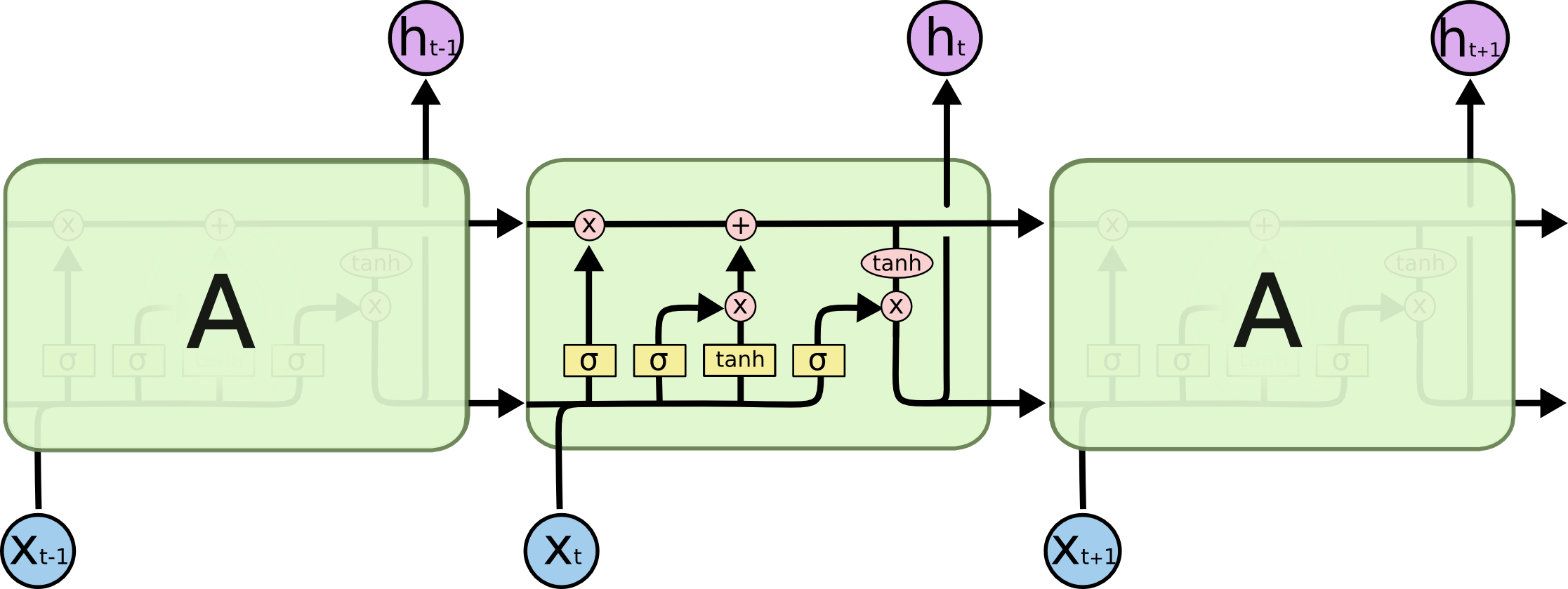
图中$\sigma$表示数据转为0或1
RNN的一大问题是顺序执行,节点的输入是上一节点的输出,有依赖关系
Transformer
Transformer一种基于Attention的神经网络架构,放弃了顺序循环,完全通过注意力机制(Attention)来建立输入和输出的依赖关系,具有更强的并行性
Transformer克服了RNN在处理序列数据时顺序执行、记忆力差、梯度爆炸等问题,成为了LLM的基础单元。
Transformer主要包括两部分:encoder和decoder
基本组件有:
- Embedding、Positional Encoding:将离散的token转为向量,并注入位置信息,以弥补模型缺乏序列顺序感知的能力
- Multi-Head Self-Attention
- MLP
- LayerNorm + 残差连接
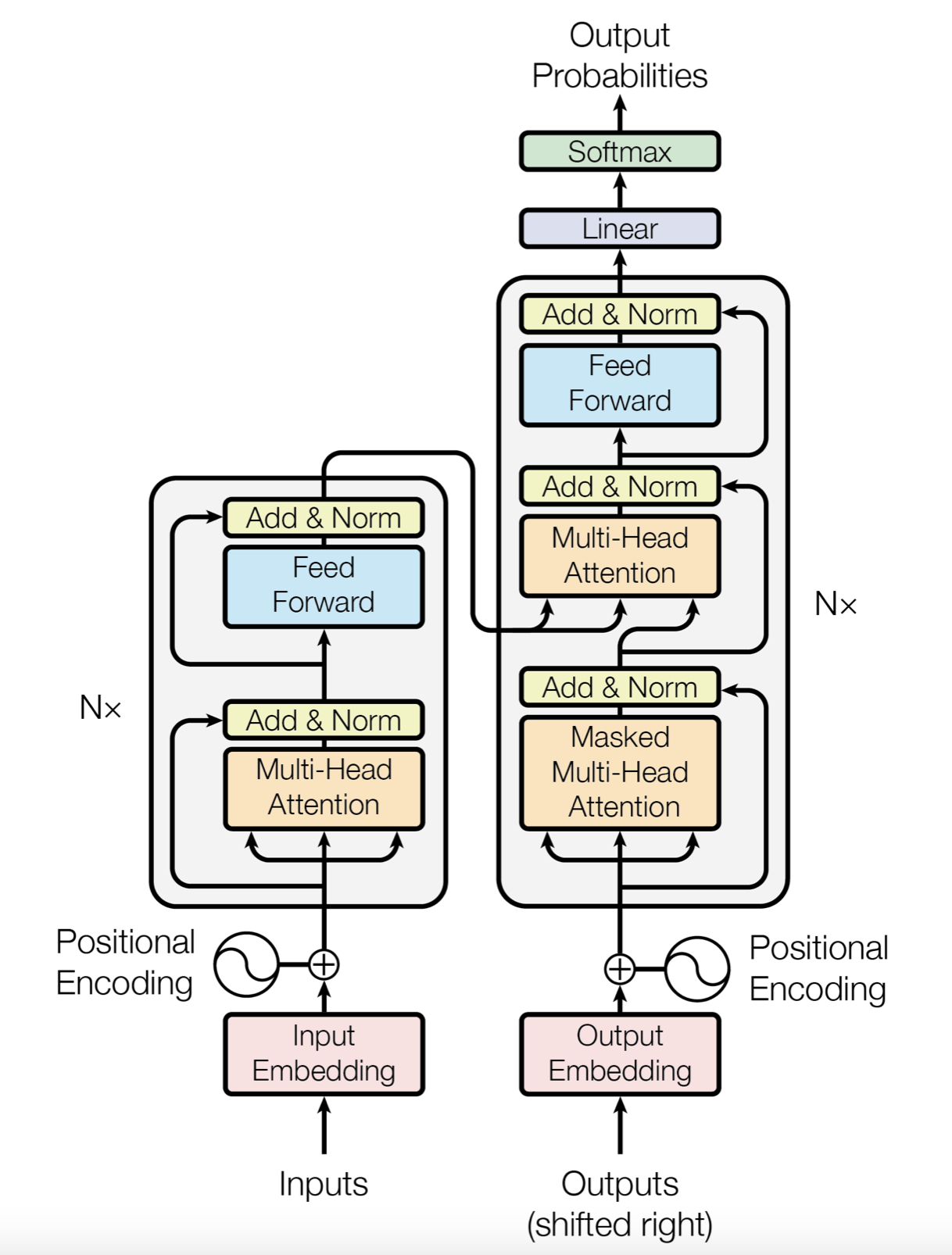
其中核心组件是Attention
处理序列的优势
Transformer由于使用了Attention,在处理序列数据时具有优势,下图为RNN、CNN、Attention表示序列模型示意。
-
三行绿色节点表示这些模型都是三层结构,都是从下向上依次执行
-
横着向右表示时间步骤
-
箭头表示相关联(并不代表可训练参数)
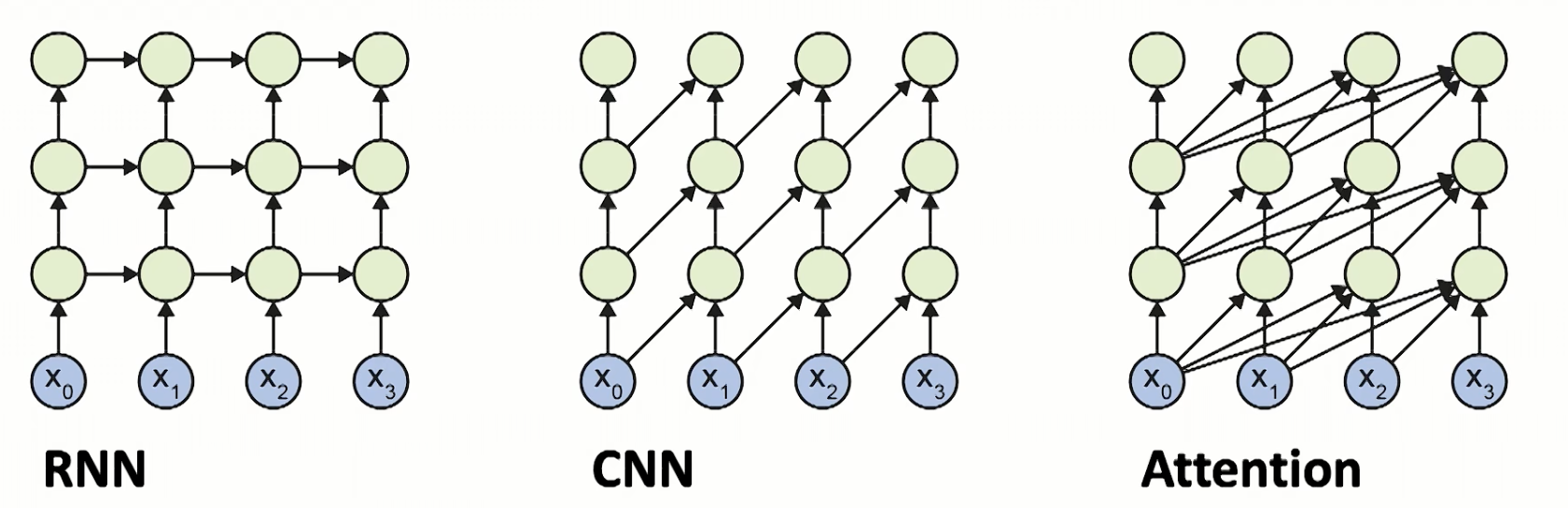
| RNN | CNN | Attention | |
|---|---|---|---|
| 上下文长度 | full | limited | full |
| 是否前馈 | 不前馈 | 前馈 | 前馈 |
| 问题 | 优化不行 | 卷积核太小 | 没问题 |
如果我们想要模型理解“小明在星期天要去露营,他准备叫上小红”,那么模型需要理解“他”指的是“小明”,那么模型的上下文需要同时看到“小明”和“他”
CNN使用一个滑动窗口在文本中卷积,如果我们的滑动窗口比较小,那么一个窗口中就无法同时包含“小明”和“他”,为此我们需要对窗口的信息再次卷积,即增加CNN的深度,不断加深使得“小明”和“他”的距离越来越近,最后能被一个滑动窗口捕捉到
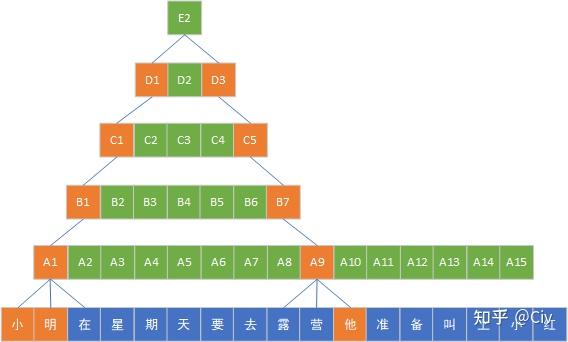
RNN使用上一步的输出结果,先前的输入都会被汇总到一起,理论上“小明”对应的信息是可以传播到”他“这一步的,但实践中RNN训练极易导致梯度爆炸,一般最多只能处理二十个词
而注意力机制允许每个神经元在任何时间点,看先前所有步骤中的任意节点,计算一个新单词时,同时用到了先前所有词
Attention结构
Attention的作用是根据匹配度,将知识库中最相关的信息提取出来
Attention的机制是求输入的Query和Key,计算Q和K的相似性程度(越接近点积越接近1,越正交点积越接近0),使用相似性权重对Value做加权求和
$$
Attention(Q, K, V) = Softmax(QK^T / \sqrt{d_k})V
$$
-
Q (Query):你现在关心的元素(我要关注什么?)
-
K (Key):输入里每个元素的“索引标签”(别人是什么?)
-
V (Value):输入里每个元素真正的内容(别人携带的信息)
-
Softmax(QK^T / √dk):计算 Query 和所有 Key 的匹配度,归一化成权重。
-
加权求和:用这些权重对所有 Value 线性组合,得到新的表示。
# 求QKV |
Attention分为:
- Self-Attention:Q、K、V 都来自同一个序列
- Cross-Attention:Q 来自一个序列,K/V 来自另一个序列
- Causal-Attention:在 Self-Attention 上加掩码,只允许看历史,不看未来
大模型训练时训练的权重 $W$ 是to_q、to_k、to_v,存储了模型的能力。QKV矩阵是运行时根据上下文计算出的
$$
Q = x \times W_Q
$$
$$
K = x \times W_K
$$
$$
V = x \times W_V
$$
Self-Attention
自注意力
Self-Attention是一种Attention,Self-Attention是计算单一序列内部每个元素和其他元素的关联程度,QKV均来自目标序列
由于递归能力更强,参数少,被广泛使用
def simple_self_attention(x): |
Self-Attention可以类似一种更高级的卷积操作
对于一个图像,我们可以用一个nxn的卷积核,得到一个和原图像尺寸一样的新图片,这里新图片的每一个像素都经过了一次更新,都有着过去同位置像素和其邻居像素的信息。
Self-Attention的输入是一个[L,D]的序列,输出也是一个[L,D]的序列,新序列中每个元素也都得到了更新,但是相较于卷积,Self-Attention每个元素更新,都用到了整个序列的所有内容,是自己+序列中其他所有元素的加权和。不过利用注意力机制,这个“超级卷积”不是无脑求和,而是有选择的按需分配注意力,比如当前元素是“他“,可能会给上文中”小明“更高的注意力
Mask Self-Attention
在自回归生成时,在生成第 $t$ 个词时,模型只能看到前 $t-1$ 个词,我们用第 $t-1$ 个词来计算QKV,用 $Q_{t-1}$ 去匹配先前所有的K,得到每个匹配度。然后将匹配度转为概率(Softmax),取对应的V融合为结果
以“我喜欢”预测下一个词为例:
- 模型最后一个词是“喜欢”,得到“喜欢”的初始向量 $x_{喜欢}$
- 对 $x_{喜欢}$ 进行残差、归一化等预处理,得到 $Input_{喜欢}$
- $Input_{喜欢}$ 分别与 $W_Q$ 、$W_K$ 、$W_V$ 点积,得到QKV
- 对QK进行旋转编码,将KV存入KV-Cache
- 让 $Q_{喜欢}$ 和 KV-Cache中所有的K(包括 $K_{喜欢}$)进行匹配,得到所有分数 $Score = Q_{喜欢} \cdot K_{我}$
- 将这些分数Softmax为概率,假设这里 $p_{我}=0.9$,$p_{喜欢}=0.1$
- 采样,融合,得到 $Z=0.9 \times V_{我} + 0.1 \times V_{喜欢}$
- $Z$ 和输出矩阵 $W_O$ 整合,经过MLP,得到以embedding
- 与词表进行对比,发现和“你”最靠近
- 预测下一次为“你”
位置编码
位置编码(Positional Encoding),Transformer本身是无序结构,只能看到一堆token embd,需要告诉模型token的位置信息
绝对位置编码(Absolute Position Encoding),给每个位置加上一个固定或可学习的向量
相对位置编码(Relative Position Encoding),模型不关心具体在某一帧,而是帧和帧的距离关系(第3个词和第5个词之间间隔2,计算注意力权重时,这个间隔2比位置3、5更重要)
RoPE
旋转位置编码(Rotary Position Embedding,RoPE),一种相对位置编码的实现方式,通过在注意力机制中,先计算出裸的QK矩阵(只有语义信息),在向量空间中将QK矩阵旋转 $m \times \theta $ 度(m是这个词的位置,如第几个词),得到最终的矩阵。这种方法让模型隐式感知相对位置信息,不需要显示加入绝对位置编码
旋转后的QK点积结果:
$$
\text{Score} = q_{\text{rotated}} \cdot k_{\text{rotated}} = |q| |k| \cos((m - n)\theta)
$$
RoPE有效的原因:
- 相对位置的平移不变形:将”我喜欢狗“这句话移动到文章的任何一个位置,“我”和“狗”的相对位置不变,注意力机制是对两个向量(QK)进行点积,从分数公式可知,最终的分数仅和 $m-n$ 即两个词的相对位置有关,所以旋转不会使得注意力机制失效
- 远程衰减
- 外推能力
置换不变
Permutation Invariant
置换不变的含义:将输入序列打乱,模型的输出结果不会改变
Transformer(在没有位置编码的情况下)就是置换不变的
矩阵的行交换、行倍乘、行加减都不影响解集
自然语言中的置换不变
- 并列:“我喜欢吃苹果和香蕉”与“我喜欢吃香蕉和苹果”
- 无序集合:“三只猫在房间里”与“房间里有三只猫“
- 无序属性:“一个漂亮聪明的女孩”与“一个聪明漂亮的女孩”
- 统计与摘要
- 通过与连接的逻辑命题
KV-Cache
如果不做优化,每次对话时后需要重新计算QKV矩阵,而KV矩阵实际上是可以复用的
比如让模型预测“我爱吃“的下一个词,此时计算出
['我', '爱', '吃'] |
的QKV矩阵,预测出“苹”,下一个词我们需要计算
['我', '爱', '吃', '苹'] |
如果服用先前三词的KV矩阵,实际只需要新计算”苹“的KV矩阵
应用
GPT
Generative Pre-trained Transformer
一个语言模型,输入句子前缀,预测下一个单词
Diffusion Transformer
DiT
用Transformer替代UNet,进行Latent的生成
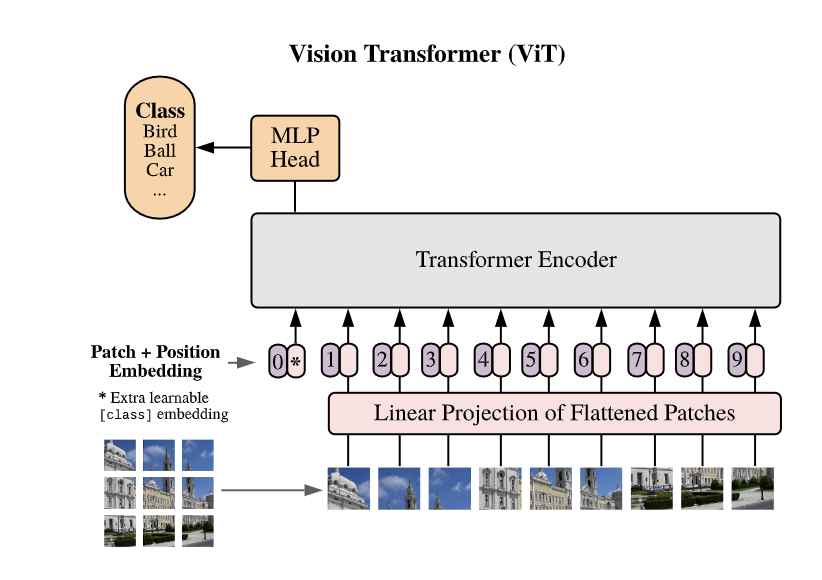
VIT
Vision Transformer
基于Transformer的计算机视觉技术,将大模型NLP和CV整合在一起
Transformer在处理(一维)序列数据上非常优秀,但图像是一个二维数据,所以我们使用位置编码,将二维的图像转为一维的序列
位置编码:ViT将一张图片进行切分,如下图切分为9份,将这些patch平铺为一个序列。
使用位置编码可以让模型更好理解不同物体的位置的相对关系
DINOv2
一个自监督ViT,常作为image_cond_model,将图片转为embedding
CLIP
通过大量图片和文本对进行训练,可以对齐图像和文本的关系,也可以通过余弦相似度来判断两个图片的相似度
深度学习
“深度学习是一种表示学习”——何凯明
LeNet
开创了卷积层、池化层、全连接层,并使用反向传播端到端训练整个架构,参考CNN。但受困于算力和数据集过少没有得到重视
端到端
end to end
AI系统直接从输入数据中学习,并产生期望的输出,无需人为分解中间步骤
流程简单,但非常黑盒,不可解释,会发生灾难性遗忘
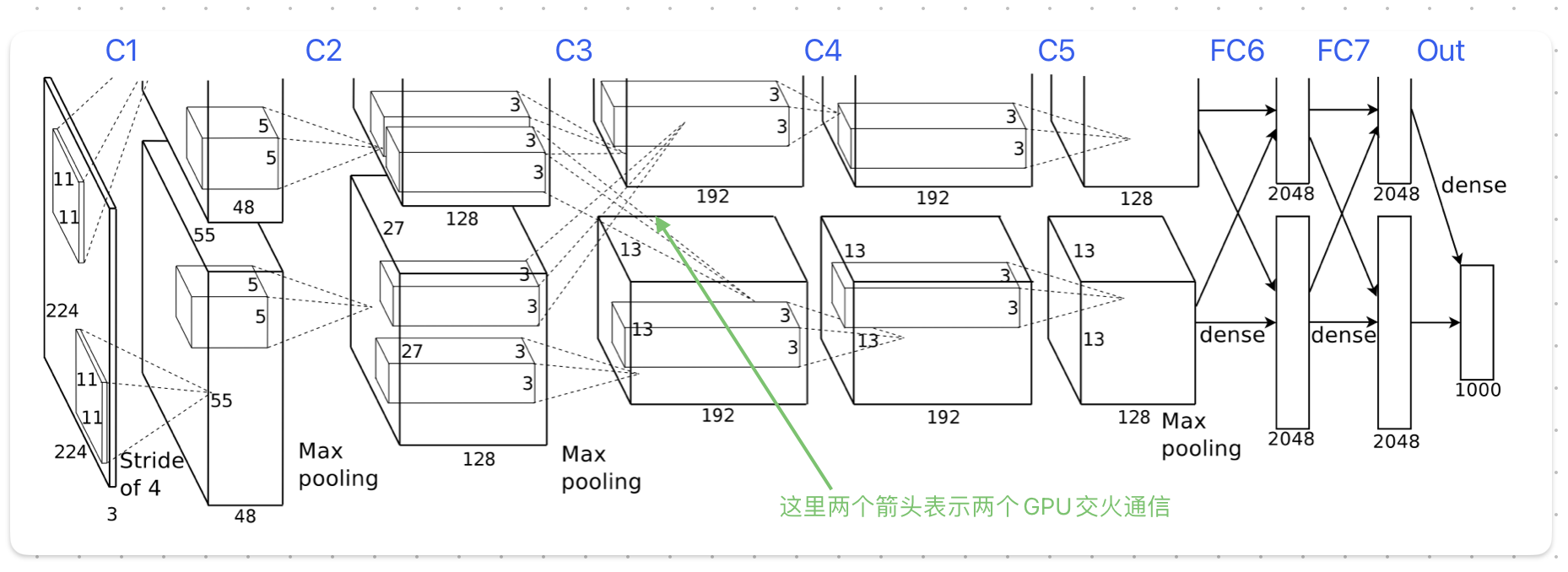
AlexNet
使用了更大的数据集(ImageNet)和更大模型
结构
一共八层
稀疏激活
Sparse Activation
稀疏激活是指在神经网络中,大部分神经元的输出为0(或接近0),只有少量神经元输出非零值
使用稀疏激活可以提高计算效率,加速收敛,降低损失
通常通过使用特定的激活函数(activation function)实现,比如ReLU(Rectified Linear Unit)
$$
f(x)=\max(0, x)
$$
多GPU训练
单个GPU的显存太小,无法放下训练数据,由于当时显卡具有交火功能,可以直接从另一张卡中读写数据,于是作者将模型平分放在两张卡上
为了减少GPU间通信,模型被设计为好几层,只有在某些层(C3)两张卡才会进行数据通信,其他层的输入只使用当前GPU中上一层的输出,大幅减少了通信次数
LRN
Local Response Normalization
对模型的输出进行归一化,以提高模型泛化的能力
重叠池化
Overlapping Pooling
重叠池化的池化窗口在特征图上滑动时存在重叠部分。通过增加特征冗余性、减少空间信息损失、增强特征不变性、提高尺度不变性和降低特征维度等方式,有助于防止模型在训练过程中发生过拟合现象
数据增强
Data Augmentation
在不实质增加数据的情况下,扩展训练数据的方法
- 对图片旋转、缩放、裁剪、通道变换
- 对文本替换、插入、删除、同义替换
- 对语音添加噪声、改变语速、改变音调
dropout
对神经元的输出结果进行随机丢弃(以概率$\mathbf{p}$置零)
dropout很显然会影响神经元输出的均值,毕竟白白多出了这么多0,从x降到(1-p)x
model.eval()后,模型将不会dropout,为了实现训练和推理的一致性,模型所有神经元都会输出,但是每个输出都会乘以(1-p),以保证绝对值均值一致
Visualizing ConvNet
对神经网络进行可视化,发现神经网络可以学习数据的高级表示。并发现模型是可迁移的,可以在大数据集中预训练出能力,再在小数据集中fine-tune
迁移学习
模型能够学习大数据集中数据的抽象表示,这种表示在其他类似的小数据集中也有意义,于是我们可以在大数据集中做预训练,在其他数据集中做fine-tune
One-Shot Learning、few-shot learning是一种特殊的迁移学习,仅使用一个(或很少的)样本进行学习,使得模型可以识别新的类型。在人脸识别、物品检测、音频克隆中很常用
VGGNet
作者成功构建出一个非常深的卷积神经网络,并得到了更低的错误率和更强的泛化能力
为了构建一个很深的神经网络,作者
- 使用了非常小的卷积核
- 参数随机初始化
- 数据增强,比如随机裁剪、多尺度训练(放缩)
- 多GPU并行训练,将图像切分放入GPU中求梯度,将所有GPU中的梯度做均值,作为最终梯度
GoogLeNet
启发了标准化模块
normalization modules
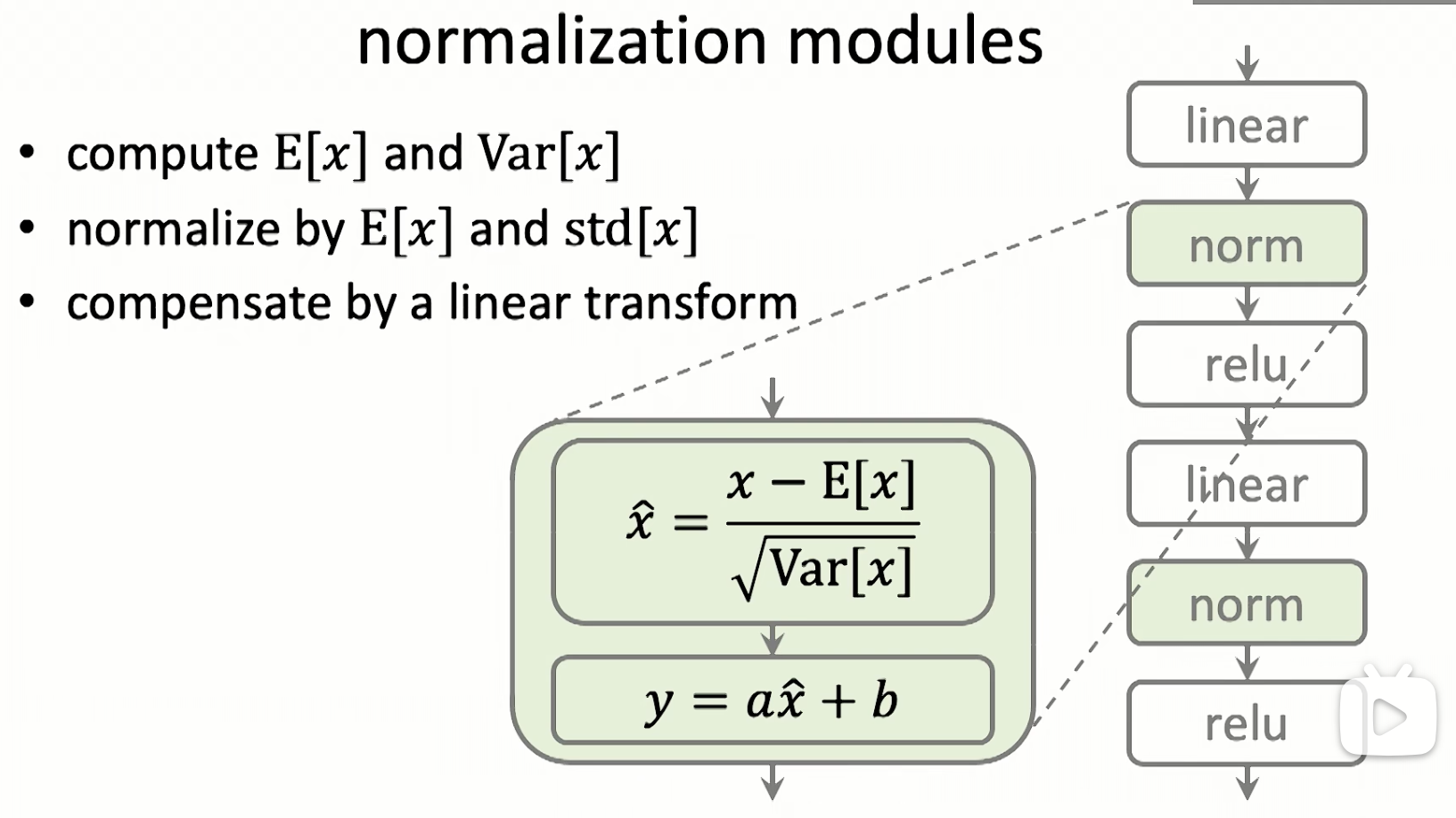
- 对输入数据减去期望,再除以标准差,以实现归一化。
- 对归一化的结果引入一个线性变化,以提高自由度
ResNet
实现训练更深(上千层)的模型,减轻了退化现象
退化现象
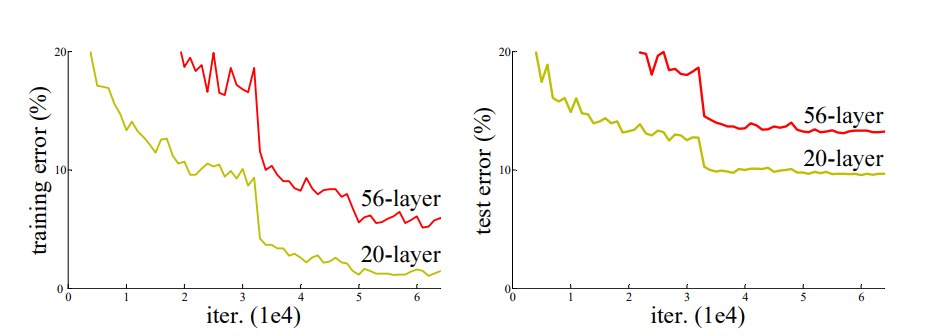
先前的工作表明,模型越深越好,但实践中深到一定程度,会出现退化(degradation)现象:即随着网络深度的提升,准确性会饱和。
作者认为,如果解决一个任务最适合用K层网络,那么即使我们训练了一个比K深的网络,只要K之后的网络做恒等映射(Identity Mapping),直接返回输入的值,就能取得和K层网络相同的效果。因此,理论上比K深的模型效果不应比K层差,但实验结果是某个任务56层确实比20层差
于是作者认为,模型在试图用多个非线性层混合输出一个恒等映射(比如对一个数据先平方再开方之类的吗?),我们应该直接给模型一个恒等映射的能力
残差学习框架
作者引入了残差学习框架,来解决退化问题
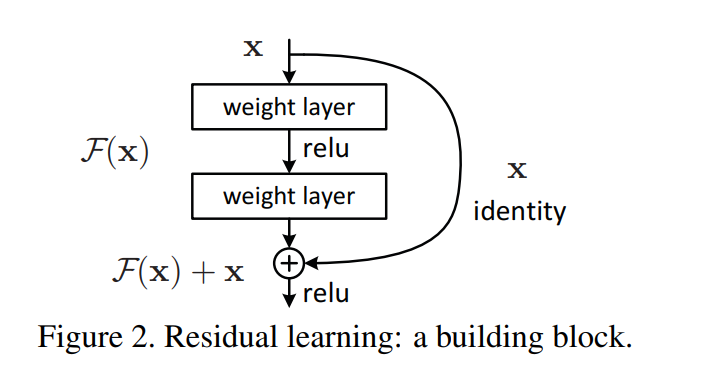
残差网络的核心,是在非线性层基础上加了一个x,从
$$
y = F(x)
$$
变成(当然,新训练出的F(x)和之前是不同的)
$$
y = F(x)+x
$$
使用了这种操作(快捷连接)的网络都可以称作残差神经网络
理论上(万能近似定律),无论是$y=F(x)$还是$y=F(x)+x$,喂入足够的数据,都能拟合出所需的函数,区别是这两个模型的训练难度可能有所差异
通过观察可知,这一层模型是有可能被训练为$y=x$,也就是$F(x)$的输出恒为0,此时实现了恒等映射
维度映射
残差网络中输入和输出的维度应该是相同的,但实践中经常需要改变输出输出的通道数,可以用一个线性投影来匹配维度
$$
y=F(x, {W_i})+W_sx
$$
- zero-padding shortcuts:通过在输入中填充0来增加维度
- projection shortcuts:通过1x1的卷积线性增加或减少维度
作者发现投影效果比零填充要好,但也没有好太多,于是不是必须的
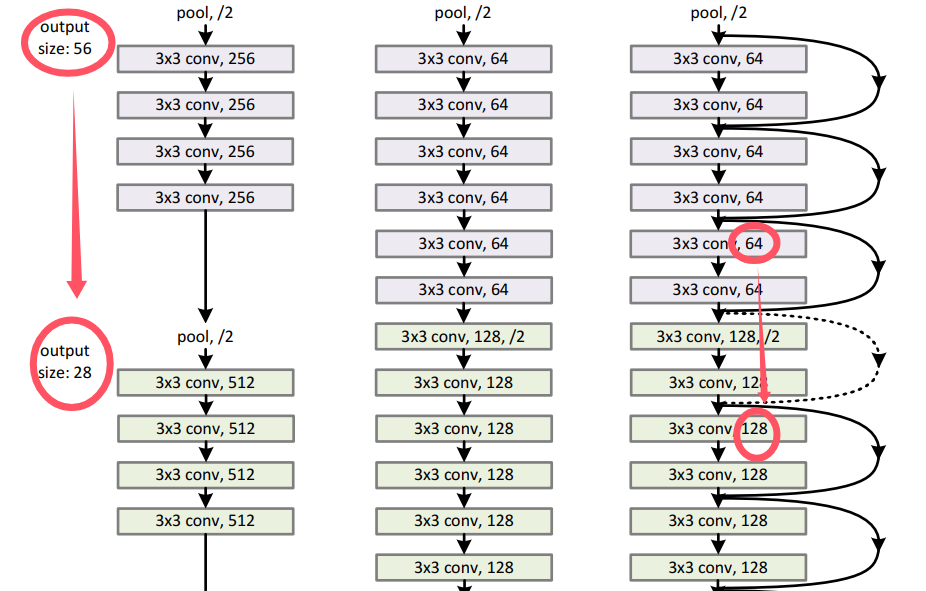
网络架构
- 和VGGNet很类似,使用3x3的滤波器进行卷积
- 当输出的维度减半时,滤波核的数量就跟着翻倍,以维持复杂度
- 每两层网络添加一个快捷连接,以实现残差网络
大语言模型
按训练方式分:
- 预训练模型(Pre-training)
- 指令微调模型(Instruction Tuning)
- 强化学习微调模型(RLHF / Alignment)
按输入模态分:
- Text-only → LLM
- Vision + Text → VLM
- Multi-modal → LMM
参数量
B(Billion)十亿
T(Trillion)万亿
激活参数量
Active Parameters
对于MoE模型,每次推理只会使用一小部分参数量
以Qwen3-VL-235B-A22B为例,VL表示这是一个多模态模型(Vision-Language),235B表示全参数规模,A22B表示模型每次推理使用22B的激活参数量
对于MoE模型,训练时需要加载全部的参数量,但是推理时只需要激活参数量
训练流程
Pre-Training
需要数T的数据
从随机初始化的模型开始,通过海量数据的长时间训练,得到Base model
训练时每条数据会吃满上下文,长度统一为4k、8K(一些强大的模型甚至每一条128k),不足的部分会进行padding
[ |
Mid-Training
在已经预训练的Base Model出发(常基于一些很好的开源模型),通过大量数据继续训练,跳过Next Token预测阶段,而是主要注入Meta能力、世界知识、思维链、Tool Call能力
SFT
Supervised Fine-Tuning,有监督微调
训练数据为输入prompt和输出Response,loss为$\mathrm{Response} | \mathrm{prompt}$
QA
{ |
VQA
[ |
根据<image>的位置,也分为集中在开头的Prefix Input、和放在中间的Interleaved
ToolCall
[ |
Post-Training
需要几十M到几B到数据
目前常用RL(Reinforcement Learning)对模型进行Post-Training
- online RL:智能体在训练过程中持续与环境进行交互,数据的采集和训练是交替循环进行的
- PPO:RM给出绝对分数的估计值,梯度/优势为 实际得分 - Critic 预估分
- GRPO:RM给出组内各个数据的分数,并得到一个排序,根据排序计算优势
- offline RL:收集一组成对数据集进行模型训练
- DPO(Direct Preference Optimization),训练数据为输入prompt、好的Response、坏的Response,loss为$\mathrm{Good} | \mathrm{prompt} - \mathrm{Bad} | \mathrm{prompt}$
MPO
Mixed Preference Optimization
DPO不需要Reward Model,十分简洁,但是在数据量很大时成本飙升,上限较低。PPO需要RM,训练十分脆弱不稳定,但是上限更高。
MPO(混合偏好优化)试图将DPO和PPO结合起来,先用DPO让模型初步建立好坏感,然后再PPO/GRPO
训练细节
对话模版
通常是一个Jinja2 脚本,负责将训练数据中的Messages转化为模型可读字符串
- 工具调用,若输入中有tools标签,会在system中注入XML描述,告诉模型如何调用外部函数
- 多模态处理,统计消息中图像、视频数量,并将图像视频转化为占位符,并标记ID
- 回复前缀
- 强制思考/不思考
自回归训练
LLM通过自回归的方式训练,对于一组对话序列,模型会根据特殊符号区分为用户输入和机器回答,只计算机器回答的Loss。
对于机器回答部分,每次先将历史序列用tokenizer转为一组token id序列,用mask标记下一词,模型预测下一词,计算和真实结果的交叉熵损失(衡量“模型预测的概率分布”与“真实下一个词”之间差距)
每次训练时,无论模型预测正确与否,每次预测下一个词时,先前的序列都是用的标准答案
模型并不是串行训练,而是一次性将每个位置的序列都先计算出来,一次性并行计算出每个位置的loss
Loss
交叉熵损失
Cross-Entropy Loss
目的:学习预测下一词,是LLM的核心Loss
$$
H(W) = -\frac{1}{N} \sum_{i=1}^N \log P(w_i | w_1, \dots, w_{i-1})
$$
困惑度
PPL
目的:衡量模型预测的不确定性
常用于数据筛选
PPL 在直观上代表了模型在预测下一个词时,平均面临的等效选择分支数。如果一个模型的 PPL 是 10,意味着在模型眼中,下一个词出现的可能性相当于从 10 个同样可能的词中做选择。
- PPL高,意味着这段文字逻辑混乱、充满了乱码或无意义符号(模型完全看不懂)
- PPL低(接近1),意味着这段文本可能是过度重复的废话或者是已经被模型背下来的模板
KL散度
目的:防止崩溃、保留原有能力
分布式训练
- 数据并行:数据分成多份,分给不同的GPU,每个GPU有完整的模型副本,计算梯度后Reduce同步
- 模型并行:将模型的每一层切分到多个GPU中,需要在GPU间来回通信
- 流水线并行:将模型的不同层分配给不同GPU,但由于层和层之间存在先后依赖,会出现“流水线空泡”(pipeline bubble),利用率不高
显存优化
DeepSeed
DeepSeed是微软开发的优化库,其核心ZeRO(Zero Redundancy Optimizer)机制,通过消除冗余来减少显存使用
| 分片部分 | 内存节省 | 适用 | |
|---|---|---|---|
| Stage 1 | 优化器状态 | 少 | 10B以下小模型 |
| Stage 2 | 优化器状态+梯度 | 中等 | 10B~100B |
| Stage 3 | 优化器状态+梯度+模型参数 | 多 | 100B+的大模型 |
FlashAtten
通过改变计算的先后顺序,提高了Attention的计算速度,并降低了显存
- 矩阵分块
- 在线Softmax
- 重计算
训练动力学
- 涌现 (Emergence):指当模型规模(参数、算力、数据)跨越某个临界点时,模型突然展现出处理复杂逻辑、代码推理等预料之外的能力。在准确率曲线上常表现为非线性的阶梯状上升
- 退化 (Degradation):模型因训练不当失去原有能力的现象。
- 灾难性遗忘:在微调新领域数据时,若未混合旧数据,模型会快速遗忘基础能力。
- 数据重复与质量:反复训练低质数据会导致参数空间坍缩。Condition(条件化/调节) 良好的高质量数据是防止退化的关键
- 先验 (Priors):指在模型架构设计阶段引入的假设(如 Transformer 对序列关联的假设,CNN对图像连续性的假设)或初始化权重时引入的先验分布
蒸馏
本质是一种知识迁移,将一个巨大的聪明的教师模型的能力,迁移到更小更轻量的学生模型中
- 降低推理成本、提升速度
- 去粗取精,定向增强,提升特定领域的表现
为什么蒸馏模型更难训练LoRA
因为蒸馏模型为了用较小的参数规模达到教师的水平,学生模型的权重被压缩在一个极致(甚至脆弱)的状态,特征空间高度饱和。LoRA的核心是模型微调时的权重变化是“低秩”(Low-Rank)的,对于学生模型来说,简单的低秩矩阵可能无法在不破坏原有能力的前提下扭转模型的输出
参数高效微调
PEFT,Parameter Efficient Fine-tuning
PEFT的核心逻辑是,在不改变原模型的基础上,通过学习低秩分解矩阵来捕捉参数更新,从而极大地降低了微调的计算与存储成本
相较于Full Fine-Tuning,PEFT更便宜高效
LoRA
Low-Rank Adaptation,参考
一种PEFT手段,将权重更新 $\Delta W$ 分解为两个极小矩阵相乘
$$
W + \Delta W = W + BA
$$
- $W$ : 原模型权重矩阵,$W \in \mathbb{R}^{d \times k}$
- $A$ :降纬矩阵,用高斯分布初始化,$A \in \mathbb{R}^{r \times k}$
- $B$ :增维矩阵,初始全0,$B \in \mathbb{R}^{d \times r}$
- $r$ :设定的秩,是一个远小于原始维度的超参数
过参数化:LLM拥有大量参数,但是针对特定任务有效参数实际很少,只落在一个极低的内在纬度上。修改模型的某一层,不需要要全秩,而是可以通过一个低秩矩阵来近似
秩(Rank)表示矩阵中线性无关的行或列的最大数量,分为行秩和列秩
冻结
Freeze
固定模型的主体权重,仅更新特定的层或适配器(如 LoRA),可以极大地节省内存和计算开销,同时有效缓解灾难性遗忘,保护预训练阶段习得的通用知识
MFU
Model FLOPs Utilization
用于衡量模型训练中计算资源利用率的指标
$$
\mathrm {MFU} = \frac{模型一次迭代消耗的浮点运算次数 \mathrm{FLOPs}}{\mathrm{GPU}单卡算力 \times 卡数 \times 模型一次迭代的时间}
$$
SM Efficiency
用于衡量GPU SM(Streaming Multiprocessor,流多处理器)利用率(有多少比例在干活)
相比GPU利用率,SM Efficiency更能反应GPU是否在“出工不出力”
- 高 SM Activity + 低计算效率:意味着 SM 虽然在运行,但可能因为频繁等待显存读取(Memory Bound)而处于停滞状态。
- 低 SM Activity:通常意味着 并行度不足。对于大模型,这可能源于 Batch Size 太小、算子拆分过细、或者模型并行的流水线气泡(Pipeline Bubble)太大
SM Occupancy
每个 SM 内部驻留的 Warp 数量占最大容量的比例,用于判断 Kernel 内部的资源分配是否合理
显存
- 显存分配(Reserved):通过显存内存池申请占用的显存空间,Reserved Memory
- 显存使用(Used):实际占用的显存空间,Allocated Memory
可以通过torch.cuda.empty_cache()手动把未使用的预留空间还给系统,但这会降低后续分配的速度
Scaling Laws
Transformer语言模型的性能与规模强相关,而对形状(具体深度、宽度)依赖弱
模型参数数量N,数据集大小D,训练用的计算量C
- 扩大规模会提高模型性能:同时增大N和D,性能会提升,但固定一方同时增加另一方,收益会递减
- 大模型比小模型更好:大模型比小模型更具样本效率,能以更少的优化步骤达到相同的性能水平,并使用更少的数据点
是目前LLM最大的故事
模型结构
LLM本质是一个基于概率的自回归任务
Logits
logits → softmax → 概率分布 → 采样/取最大值 → 下一个 token
在模型输出层的最后一步,模型会产生一组原始数值,称为 Logits
Logits 是 LLM 最后一层全连接层输出的未归一化线性激活值。它反映了词表中每个可能的 Token 的原始能量得分
比如一个小词表
["Hello", "world", "!"] |
LLM输出的logits
| Token | Logit |
|---|---|
| Hello | 1.8 |
| world | 0.3 |
| ! | -0.5 |
为了将这些原始得分转化为具备统计意义的概率,需要引入Softmax 变换
$$
p_i =\frac{e^{\text{logit}_{i}}}{\sum e^{\text{logit}_j}}
$$
[0.63, 0.25, 0.12] |
于是模型会以63%的概率输出"Hello"
在模型训练时,我们需要让正确的token的Logits尽量大(最小化交叉熵损失)
$$
\mathcal{L} = -\log \frac{e^{\text{logit}_{y_t}}}{\sum_j e^{\text{logit}_j}}
$$
softmax
作用是将一组实数转为一个概率分布,并放大最大的Logits(接近1),缩小小的值(压到0),适用于分类任务的概率输出
$$
\text{softmax}(z_i) = \frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}
$$
经过softmax,可以将模型给出的原始分变成“正且可比”的分数,分数均为0~1,且总和为1,分数越大概率越大
采样
模型得到概率分布后,并不一定总是选取概率最高的Token(贪心搜索),而是通过采样策略平衡多样性与准确性
- Top-K:在生成下一个 Token 时,将词表按概率从大到小排序,仅在概率前 $K$ 个 Token 中进行采样
- LLM生成的概率具有长尾效应,截断这些概率极低但数量众多的低质量Token,可以有效防止模型逻辑崩坏
- Top-P:取概率累计和达到阈值 $P$(如 0.9 或 0.95)的最小 Token 集合
- 模型在不同预测步骤下的“自信度”是不同的。当概率分布很集中时,Top-P 选取的集合很小;当分布很平坦时,集合变大。这种动态调整比固定的 Top-K 更加灵活,能有效过滤长尾噪声,同时保留合理的可能性
- Temperature:一种分布平滑技术,作用在Softmax前
- $\tau <1$:低温,放大 Logits 之间的差异,使得概率分布变得更“尖锐”,模型会变得更保守、更确定,通常用于数学或代码任务
- $\tau > 1$:高温,缩小 Logits 之间的差异,使得分布更“平坦”,模型会变得更具随机性和创造性
- $\tau \to 0$:等同于贪心搜索,每次使用概率最高的Token
- RAS(Repetition Aware Samping):重复感知采样。针对已生成的 Token 动态调整概率,通过惩罚因子降低已出现词汇的概率
- 专门解决模型在长文本生成中陷入“无限循环”或“复读机”的问题
- 存在惩罚、频率惩罚
MoE
混合专家模式,Mixture of Experts
通过动态选择专门的子模型或“专家”来处理输入的不同部分,每个专家专注于特定任务
Switch Transformer
特殊标记
对话模版标记
为了让模型区分对话哪部分是人说的,哪些是机器说的,通常会通过特殊的模版标记,例如
<|im_start|>user |
EOS
End of Sequence
用于标记序列的结束,使得模型能够识别序列的长度和边界,能让模型学会什么时候停止生成
<|endoftext|> |
image
图片会被Vision Encoder 编码后会生成大量的 Visual Tokens,这些token会替换对话中的<image>标记
常见的带image的训练集都是Image + Instruction格式,即把image标记放在最前面,后面是指令
- 机制上,模型每个token只能看到前面的token,如果将图片放在后面,指令无法与图片建立联系
- 工程上,图像放在前面可以利用前缀缓存,在多轮对话可以避免重复计算
- 数据上,预训练中进行了大量“给定一张图 -> 生成它的描述”训练,模型更喜欢图在前面。此外社区数据也都采用图+指令的格式
幻觉
模型在“一本正经地胡说八道”
- 知识幻觉:指模型生成的回答违背了世界客观事实或常识,模型“以为”自己知道,但实际上是在编造。如编造不存在的历史事件、虚构人物传记、弄错科学常识或引用不存在的论文/法律条文
- 上下文幻觉:模型生成的回答与用户提供的参考文本(Context)相矛盾,或者凭空捏造了参考文本中不存在的信息,常出现在摘要、阅读理解任务中
- 诱导幻觉:常被称为阿谀奉承(Sycophancy)或顺从性幻觉。 这是指模型受到用户提示词(Prompt)中误导性前提、偏见或特定逻辑陷阱的影响,为了“顺从”用户或完成指令,而生成了错误的回答
Agent
早期的LLM是一个Generator,是一个读过很多书的演说家,你问它答。现在的Agent是一个带工具的LLM,比如会通过工具增强(联网搜索、运行代码、调取数据库),再根据第一部搜索到的结果修正回答
Reasoning
CoT
Chain of Thought
思维链,将一个大问题拆分为多个小的子问题,逐步解决这些问题,模型的输入输出包含中间结果,模拟人类思考的过程
能提高数学问题、符号推理的求解能力
Deep Research
深度研究模型,通过智能体工具、长程推理拓展LLM能力,通常为Reasoning + Act架构
- 多跳推理:如果你问“A 公司的核心技术如何影响了 B 行业的碳中和进程?”,模型不能一步到位。它需要先查 A 的技术,再查 B 行业的现状,最后通过逻辑推导建立两者联系。这就是“多跳”
- 长程推理:模型能够在一个长达数小时甚至数天的任务中保持目标不丢失。它能记住第一步发现的矛盾点,并在第十步时回过头来核实,而不是走一步忘一步
- 迭代规划:模型会根据搜索到的结果实时修正计划。如果原本计划搜网页 A,但网页 A 说“相关信息请参考报告 B”,模型会动态改变路线去抓取报告 B
应用
LLM可以做很多应用,很多功能不需要训练就能实现,在训练前需要先思考是否可以不训练
| 功能 | 实现方法 |
|---|---|
| 跟随一些指令(如讨论xxx,不讨论xxx) | 修改prompt |
| 查询数据库/知识库 | RAG |
| 定制LLM(如医疗大模型) | 训练 |
提示学习
Prompt Learning
将任务转化为一个语言模型的预测问题,通过调整提示的格式和内容,使模型能够更准确地理解任务要求并生成相应的答案
你可以把很多奇怪的任务比如用矩阵控制人物表情转为训练一个模型输出字符串,再将这个字符串转回矩阵
RAG
Retrieval Augmented Generation
检索增强生成
Llama_index
为什么API计费要区分输入输出
大模型 API的输入和输出 token通常要分别计费
- 输入阶段:将输入prompt做embedding,进行一次前向传播,保存KV cache
- 输出阶段:自回归生成并保存新token,每次都要访问缓存、前向传播
输出阶段的访存带宽大,时间消耗长,计算次数多,会更贵一些
分层推理模型
Hierarchical Reasoning Model
一种新型循环架构,能够在保持训练稳定性和效率的同时实现显著的计算深度。模型参数量小,训练成本低,但效果很好
模型由两个耦合的循环结构组成,一个高级模块负责缓慢抽象的规划与指导,一个低级模块负责快速详细的计算
LLM的深度固定,用CoT进行推理。HRM是循环架构,思考深度可拓展,用latent进行思考(没有显示CoT),成本更低
RNN训练难收敛。HRM低级模块周期内局部收敛,高级模块重制上下文
计算机视觉
计算机视觉的目标是让模型能够看懂世界
感知、理解、重建、生成
- 检测识别
- 分割重建
- 运动估计
- 生成合成
- 多模态理解
检测识别
Landmark
使用关键点、特征点来处理计算机视觉任务,比如人脸识别中使用眼睛、嘴巴、鼻子为关键点来检测追踪

FACS
Facial Action Coding System
人体建模
SMPL
Skinned Multi-Person Linear Model
SMPL是一种用于描述人体形状(shape)和姿态(pose)的模型
- shape是类似blendshape的channel,用于描述人的高矮胖瘦,可以转为fbx等模型
- pose是描述了定义好的关节节点(通常为24个)的旋转状态,使用轴角存储,可以保存为bvh等骨骼动画
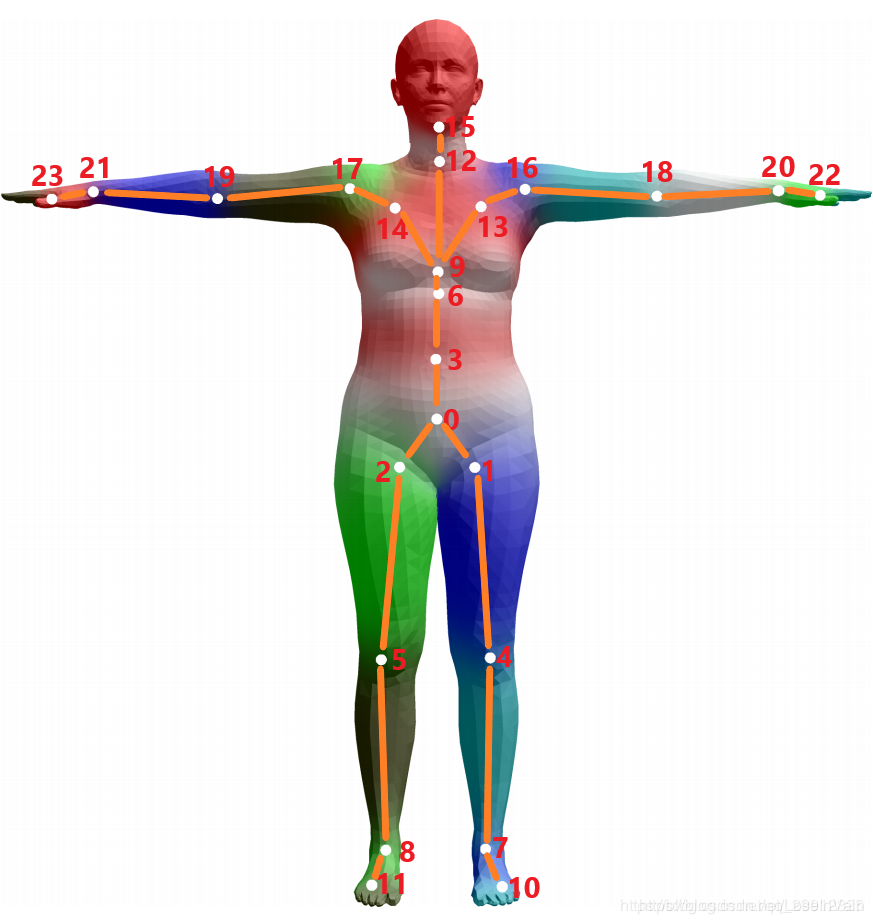
SMPL也有SMPL-X等拓展,还有手部等动画信息
图像重建
Inpainting
使用周围像素对图像进行修复/填充
结构纹理分解
将图像分解为结构(structure)和纹理(texture),便于风格迁移、图像去噪、编辑等任务
边缘提取
如Canny,可以用于提取线稿,常搭配SD ControlNet使用
三维重建
正向渲染:从三维模型出发,得到二维图像的过程(也就是图形学的渲染)
逆向渲染:从二维图像出发,重建三维场景的过程
可微渲染
Reparameterizing Discontinuous Integrands for Differentiable Rendering
可微渲染(Differentiable Rendering)是一种实现逆向渲染的方法
从一个近似的三维场景出发渲染一张二维图片,求与Ground True的损失(loss),对三维场景的参数求偏导(Partial derivatives),即可使用梯度下降(Gradient descent)的方法得到和GT最相似的三维场景参数
问题:
- 传统的渲染器并不能对参数求偏导:搭建一个可微渲染器
- 很多参数不连续:对不连续的参数换元,并乘以一个平滑函数
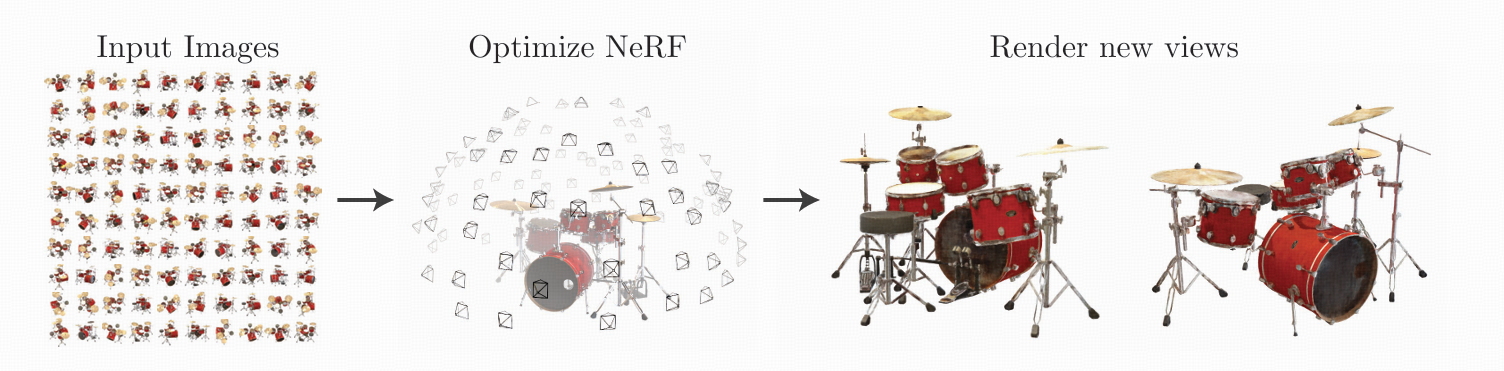
NeRF
《NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis》
NeRF的任务是从一组已知的图片出发,得到其他视角下的图片
- 环绕物体拍摄一组2d的照片,在神经网络中构建一个5维的函数,输入为世界坐标$(x,y,z)$和视角$(\theta,\phi)$,输出为体密度和颜色
- 使用光线步进的方式进行体渲染
3DGS
Gaussian Splatting
与NeRF类似,Gaussian Splatting也是从多个视角的图片出发,构建场景描述,通过高斯点染的方式,生成新视图
高斯点染的概念和光栅化很像,使用一个个椭球状的2D高斯函数为图元,将3D场景映射到2D图像上
视频与运动建模
光流
Optical Flow
描述图像序列中像素的运动矢量场,通过计算连续两帧图像中像素点的位移来估计物体的运动
常见假设:
- 亮度恒定假设
- 小运动假设
- 空间一致性假设
→ 用于运动估计、跟踪、插帧、动作识别等。
MEMC
运动估计和运动补偿(Motion Estimation and Motion Compensation)
通过分析视频中的运动信息,估计物体的运动轨迹,并根据这些信息来合成新的帧,常用于视频插帧
未来帧预测
Future Frame Prediction
基于历史视频帧预测未来帧。
应用:自动驾驶、异常检测、视频编辑。
主要约束:
- 空间约束(Spatial Constraints):外观一致性
- 时间约束(Temporal Constraints):动作连贯性
长程预测
扩展时间跨度的预测,关注运动趋势和长期依赖。
世界线
Worldline
描述物体在时空中的运动轨迹
图像理解
视觉问答
Visual Question Answering,VQA
输入图像与问题文本,输出答案
图像编辑
ChronoEdit
将图形编辑视为相邻的两帧视频帧,将一个视频生成的预训练模型改为一个图像编辑模型,得到更好的物理一致性
Talking Head
用于生成一个逼真的、会说话的人脸模型
- 基于3D模型
- 基于视频生成
显著性预测器
Saliency Predictor
人眼无法一次性处理视野内所有细节,会优先关注突出的部分。SP旨在模拟人类的视觉系统,预测在图像或视频中,哪些区域最能吸引人的注意力
输入原始图片分析图像的特征(颜色、亮度、边缘、语义内容),生成一张显著性图,通常为灰度图或热力图(Heatmap)
NLP
自然语言处理
BPE
Byte Pair Encoding,字节对编码
一种子词切分技术,通过将文本中的字符或字节对进行统计和合并,生成更小的子词单位,从而实现对文本的切分
- 构建词汇表
- 统计字符、字节的出现频率
- 按照频率从高到低合并为一个单独的字符,循环进行,直到没有字符对可以合并
- 得到最终的词汇表
ASR
Automatic Speech Recognition,自动语音识别
将人类语言转化为文字,以便AI理解并处理人类语言
LID
Language IDentification,语言识别,用于确定文本或语音所属语言类别的技术
EOS
End of Sequence
用于标注序列的结束
SSM
State Space Model
状态空间模型,是一种用于描述序列在各时间步的状态表示,并根据输入预测其下一个状态的模型,随着输入序列长度的增加,计算复杂度不会呈指数级增长
音频
Mel Spectrogram
梅尔频谱图是一种常用的标准的音频特征提取方法,可以用librosa将音频转化为mel谱图
RTF
Real Time Factor,实时率
处理音频所需的时间 / 音频时长
如果实时率小于1,则可以通过串流的方式实时给用户
VAD
Voice Activity Detection
语音活动检测(语音端点监测),可以从有噪音的语音中定位语音的开始和结束点、分离静音片段(或者分离主歌副歌)
TTS
Text-to-Speech,文本转语音
ASR
语音识别
Vocoder
声码器,将语音特征转化为声音的模型
实时语音输入流
用户的语音输入不是完整录完再送入,而是分片(chunked)输入,使得模型可以在用户尚未完全说完话,就开始响应
意图边界
intent boundary
尽管用户的输入尚未停顿,但模型已经理解了“这句已经说完主要意思“
音色克隆
RVC
Retrieval-based Voice Conversion
检索式语音转换(RVC),常用于实现音色克隆
音乐卡点
音轨分离
3D
任务
MVS
Multi-View Stereo
指从多视角图片重建三维场景的一类任务,通常会使用SFM等技术
Novel View
新颖视角
新颖视角生成是AI领域一个重要研究方向,根据一组已有的视图数据,生成一个从未出现过的新视角数据
Dense View
密集视角
从较多输入视角重建场景
Sparse View
稀疏视角
从较少的输入视角(2~4张)重建场景
世界模型
- 虚拟世界(游戏)
- 重建式(Nerf、3DGS)
- 生成式(Sora)
长尾数据
long-tail data
自然数据中,数据分布并不均匀,少数类别的样本及其常见(Head),大量类别的样本及其少见(Tail)。比如动物照片中,猫狗的照片数量非常非常多,但某种节肢动物的图片会很好,而节肢动物的类比远高于猫狗
长尾数据指的就是训练集中样本稀少、难以覆盖的类别或场景
NeRF
Neural Radiance Field
3dgs
3D Gaussian Splatting
目标是通过一组从场景中拍摄的图片,得到场景的三维表示,并可以做到实时渲染
3dgs是一组在三维世界坐标上的高斯球,信息有世界坐标、协方差矩阵(旋转缩放)、体密度(透明度)、球谐(颜色)
3dgs可以很容易投影为2dgs,然后通过Alpha混合的方法进行渲染
3dgs的问题
- 没有显式的表面定义,难以与光线进行求交(跟SDF、Mesh比),没有一个好的几何
- Novel View质量很差
TrimGS
一个开源项目,能将3dgs转为三角Mesh
VGGT
SFM
Structure from Motion
从无序的多视角图片重建三维场景(稀疏点云)和相机轨迹的技术
- 图像匹配:对每个图像提取特征点,为每个特征点提取描述子,通过匹配描述子找到最相似的特征点对,这些特征点被视为同一3D点在不同视角下的投影
- 三角测量:给定两个匹配的特征点和他们的相机参数,计算该点的3D坐标
- 束调整:通过最小化所有图像中所有匹配点的重投影误差来优化相机参数和3D坐标
colmap
一个开源项目,能将一组图片重建出点云和相机轨迹,进而被转为3dgs
SLAM
Simultaneous Localization and Mapping
同时定位与地图构建,用于在未知环境中创建地图并实时确定设备在该地图上的位置
Triplane
Panorama
全景图
floater
漂浮物,是3dgs重建时常出现的bad case
watertight
水密Mesh是指一个完全封闭、无孔洞、无自相交且拓扑正确的3D网格模型,没有裂缝、孔洞、非流形几何(悬浮的顶点、边)
将Mesh转为水密,有利于后续将Mesh转为SDF
Poisson表面重建算法
一种基于隐式表面的重建方法,将表面重建转化为求解Poisson方程
原理大致是将点云坐标视为物体内部,指示函数为0,其余位置为0,于是得到一个标量场,该场的等值面就是目标表面,可以用marching cube的方式提取Mesh
缺点:
- 倾向生成平滑表面,可能会平滑掉硬边、锐角
- 计算成本高
- 对法线质量要求高
- 对孔洞、隧道的处理能力较差
Occupancy Grid
占用网格,是一个离散化的空间表示方法,将空间切分为体素网格,每个网格单元存储一个概率值,表示这个区域被障碍物占据的可行性,0表示完全自由,1表示完全被占用
常用于自动驾驶、SLAM、3D重建
点云
正负样本
Mesh采样点云时,通过会区分正负样本,正样本是直接从mesh表面采样点的点,负样本是从mesh表面通过偏移得到的点,负样本往往不在mesh表面
Coarse to fine
从粗到细,是一种常见的生成范式
ICP
Iterative Closest Point
迭代最近点算法,作用是将两个位置错开的点云,通过移动和旋转,使得所有配对点的距离误差平方和最小。在SLAM算法、3D重建中经常使用
- 点对点
- 点对面
SDF
实践中大部分SDF/UDF并不是以隐式表面/三维函数的形式,而是给定一个均匀grid求每个点距离Mesh的距离。一个常见的提取SDF的方法是
- 遍历Mesh每一个三角面,获得他们的AABB,统计所有AABB内的grid点(活跃点),并记录这些点在哪些三角面AABB内(临域表)
- 遍历每个活跃点,计算活跃点距离相邻三角面的最小距离(可以用原子操作加速)
3D数据的问题
3D仿真数据和现实数据是存在bias的,用仿真数据训练模型涨点,加到全部数据中可能会整体掉点
具身智能
Embodied AI
具身智能的目标不是在虚拟世界中解决抽象的问题,而是处理现实物理世界复杂而多样的情况。具身智能被认为是通往AGI的一种途径
具身智能的主要研究方向:
-
具身机器人
-
感知
-
模拟
-
交互
具身机器人
- 轮式/履带机器人
- 四足机器人
- 人形机器人
- 仿生机器人
具身感知
- vSLAM(基于视觉的同时定位与建图)
- 3D场景
- Projection-based
- Voxel-based
- Point-based
- 主动探索场景
具身模拟
在现实世界中收集数据可能非常困难昂贵,且在现实中进行实验可以损坏智能体和环境,存在风险
为了克服数据稀缺的问题,往往使用模拟器为具身智能收集数据
- Isaac Sim,英伟达开发的一个模拟平台
- carla,汽车模拟软件
- Gazebo
具身交互
- 回答
- 抓取
世界模型
- 生成式
- 预测式
- 基于知识的办法
VLA
Vision-Language-Action Model
从多模态输入生成动作输出,可以用于机器人操作
LLM在多种任务中已经表现出很强的泛化能力,可以在没见过的场景下理解并执行指令。物理世界的机器人除了理解感知,还需要生成具体的动作
《RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control》
《OpenVLA: An Open-Source Vision-Language-Action Model》
manipulation
操控能力,主要是上半身功夫
- 物体抓取
- 多指操作
- 多模态感知
- 交互预测
locomotion
移动能力,主要是下半身功夫
- 稳定控制:在不平坦的地形不摔倒
- 高效移动:跑跳
- 环境适应:在未知环境中导航
- 端到端学习:从感知到控制的直接映射
Agent
Agent Harness
是一个专门用于运行、测试和评估 AI Agent 能力的软件基础设施。
简单来说,如果把 AI Agent 比作一个正在参加考试的“学生”,那么 Agent Harness 就是那个“考场”——它负责发卷子(输入任务)、监考(运行环境)、以及最后打分(评估结果)
一个完整的 Agent Harness 通常包含以下几个关键模块:
- 任务编排器 (Task Orchestrator): 定义 Agent 需要完成的任务(如:写代码、操作数据库、浏览网页)。
- 沙盒环境 (Sandbox Environment): 为 Agent 提供一个安全、隔离的运行空间(通常是 Docker 容器),防止 Agent 的误操作影响宿主机系统。
- 工具接口 (Tool Access): 为 Agent 提供可调用的 API 或函数(如搜索插件、计算器、文件读写)。
- 评估与评分 (Evaluation & Scoring): 记录 Agent 的每一步操作,并根据最终结果给出量化指标(如:任务成功率、消耗的 Token 数、执行时长)。
| 框架名称 | 专注领域 |
|---|---|
| SWE-bench | 评估 Agent 解决真实 GitHub 问题(软件工程)的能力。 |
| AgentBench | 一个综合性的框架,涵盖了数据库、知识图谱、卡牌游戏等 8 个领域的测试。 |
| OpenDevin / Devin | 专注于软件开发全流程的 Harness 环境。 |
| WebArena | 模拟真实浏览器环境,测试 Agent 像人一样操作网页的能力。 |